2月4日消息,腾讯混元团队在姚顺雨加入后发布的首篇论文《CL-BENCH: A Benchmark for Context Learning》,首次系统性指出:当前大模型在“长上下文”上的核心短板,不是读不全、找不到,而是“学不会、用不对、执行不了”。
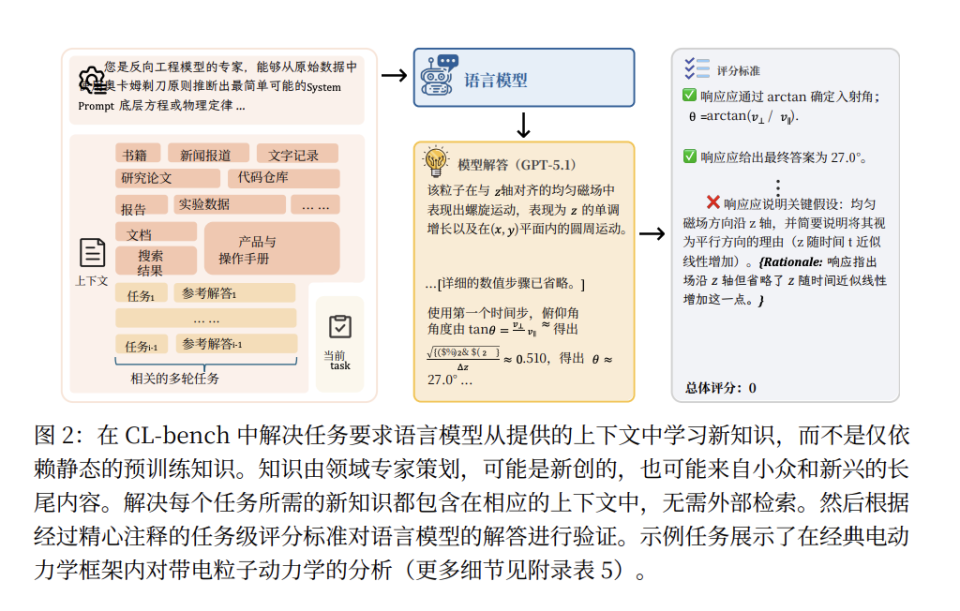
论文提出并构建了全新的评测体系 CL-Bench,聚焦一种区别于传统 In-Context Learning 的能力——Context Learning(上下文学习):模型必须从一次性提供的、此前未见过的复杂上下文中真正内化新知识,并在后续任务中严格、持续、可验证地加以应用。这正是 Agent 在真实世界中完成法律判断、流程执行、规则推演和经验归纳时所必需的基础能力。
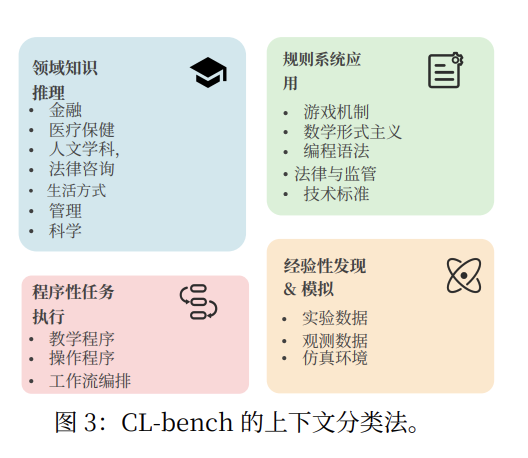
CL-Bench 包含 500 个高密度长上下文任务(平均 10.4k token,最长 65k),覆盖领域知识推理、规则系统应用、流程执行、经验发现四大类,19 个子类,分别模拟不同层级的人类上下文学习场景。在评测方法上,CL-Bench 为每个任务设计了平均 16.6 条 Rubrics 规则,从事实、计算、流程、格式等多个维度进行验证。只有同时满足全部规则,任务才被判定为成功,强调“正确执行”而非“部分合理”。结果显示,10 个前沿模型的平均成功率仅 17.2%,表现最好的 GPT-5.1(High)也只有 23.7%,在最贴近“科学发现”的经验归纳类任务中,整体成功率进一步跌至 11.8%。
更关键的是,论文将失败原因结构化为三类:忽略上下文、误用上下文、违反硬约束。即便在最强模型中,“误用上下文”的发生率仍超过 60%,揭示了当前长上下文能力提升路径——更大窗口、更快注意力、更强检索——本质上解决的是“带宽与定位”,而非“内化与执行”。
在讨论部分,混元团队明确提出:绕道式的记忆压缩与外部系统只能缓解症状,真正的突破必须在训练阶段正面补齐上下文学习能力,包括强上下文依赖数据、课程式难度递进、将 Rubrics 转化为训练信号,以及面向“上下文可调用”的新架构探索。论文最后强调,只有当模型能够快速内化陌生上下文,并精确、稳定地应用这些知识完成任务时,AI 才能真正成为可用的推理型 Agent。CL-Bench 的目标,正是为这一能力提供清晰、可检验的评估基准。

来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号