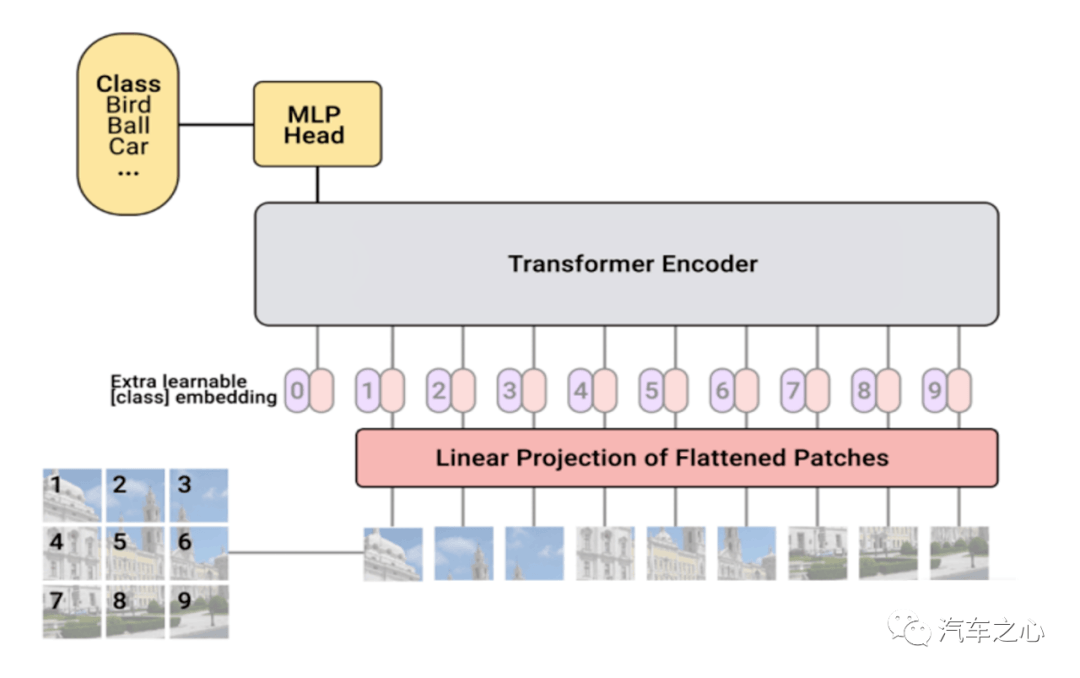
Vision Transformer 的典型网络结构
Transformer 模型在近两年横扫 NLP 领域,并随着技术发展开始征战图像视觉。在中美两地,最近有两家自动驾驶头部公司分别同时宣布将 Transformer 引入到自动驾驶系统中,来实现系统感知智能与认知智能的大幅优化。
其中一家是特斯拉。6 月 20 日,在计算机视觉领域的顶级峰会 CVPR 2021 上,特斯拉 AI 高级总监 Andrej Karpathy 首次对外阐释了特斯拉全新自研的超级计算机 Dojo,Dojo 几乎一出道就成功卡位了全球第五大(算力规模)的超级计算机。
而 Dojo 出道身后,Karpathy 还在软件算法领域释放了一个重要的信息:引入 Transformer 进行大规模的无监督学习。
无独有偶,中国自动驾驶公司毫末智行也在同一个月内公布正利用 Transformer 进行超大规模的感知训练,并且后期有可能将 Transformer 引入到规划和控制中。毫末智行是国内少有的「车企 + 技术公司」的自动驾驶研发样板,也有人称它是中国的 Cruise。
毫末智行 CEO 顾维灏近期讲到,「据 6 月最新公开论文数据显示,Vision Transformer 的参数量已经达到 20 亿之多,经过在 30 亿规模数据集上的训练,其性能达到了业界最高水准。Vision Transformer 是最适合超大数据集的技术,也是非常适合毫末智行的技术。在自动驾驶领域,特斯拉有这么多数据,未来毫末智行也会有。这是毫末智行突破重围的关键,也是未来坚实的技术壁垒。」
Transformer 最早是由 Google 提出用于机器翻译的神经网络模型。因为其通过一维卷积+注意力机制的设计,抛弃了 NLP 中常用的 RNN 或者 CNN,取得了非常不错的效果。并且 Transformer 因为出色的算法并行性,十分适合 GPU 的运算环境,因此这一技术快速流行起来。
随着 2020 年 Vision Transformer ( ViT )横空出世, 目前其已经成功涉足分类、检测和分割三大图像问题,并迅速刷遍了业界的各大榜单。
当下中美两大自动驾驶玩家,忽然在同一时间为同一种技术趋势站台,也充分表明了 Transformer 非凡的潜力。
Transformer 来袭,CNN 的地位尴尬!
自 2012 年以来,CNN 已成为视觉任务的首选模型。
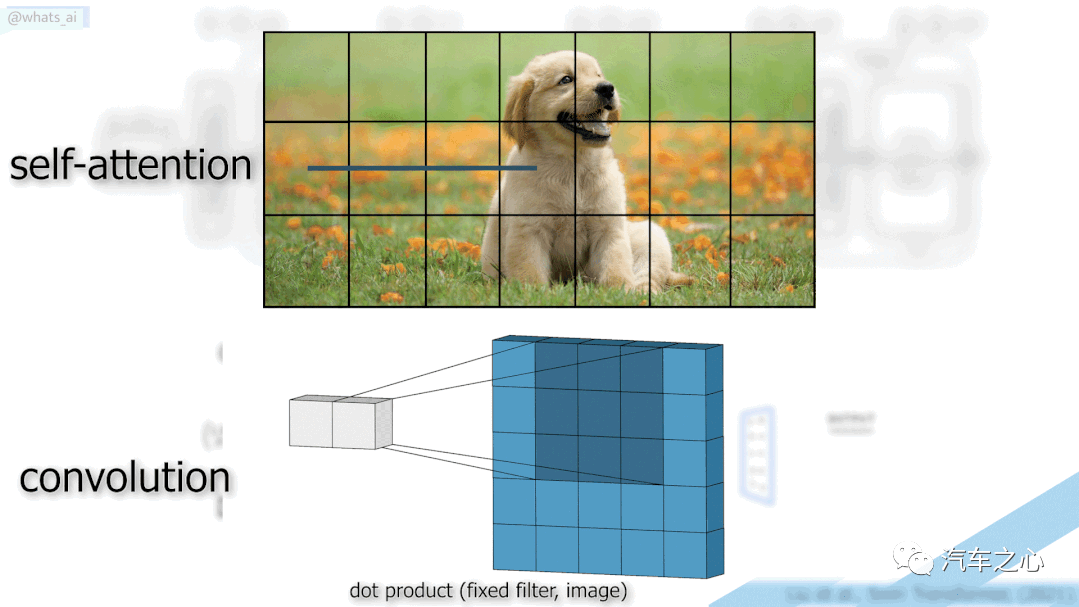
CNN 通过卷积层,构造了一个强大的广义过滤器,不断对图像中的元素筛选压缩形成通用结果。对于常规分类任务的效果很强大,但它通常过于依赖某个局部信息,从而导致一定程度的不可靠性。
然而,Transformer 抛弃了传统的 CNN 和 RNN 建模路线,整个网络结构完全是由 Attention 机制组成,核心就是多头注意力机制(Multi-Head Self-Attention)。
这种多头注意力机制能够抽象地理解整个图像不同区域语义元素之间的关系。
这就像被打乱的拼图游戏,Transformer 通过图片像素之间关系,依然能够记住它们的组合顺序。
这种机制,让 Transformer 在两种场景下,具备比 CNN 更明显的优势:
(1)大规模数据训练
随着训练数据量的增长,CNN 性能所带来的收益会逐渐呈现过饱和趋势。而 Transformer 的饱和区间很大。
有研究发现,当预训练数据集增大到 1 亿张图像时,训练后的性能 Transformer 开始优于 CNN,而数据增大到 10 亿张,两者的性能差距变得更大了,这就意味着 Transformer 在利用大数据的优势上面,是要明显优于 CNN。
而自动驾驶是典型的需要海量数据进行超大规模训练的系统。搭载自动驾驶系统的车辆上路之后,几乎可以获得无限量的数据。
目前,特斯拉有数百万辆搭载 Autopilot 的车辆在路上行驶,而毫末智行通过与长城的合作也可以获取到大量的真实路测数据。
因此,自动驾驶这样的应用场景,恰恰是完全释放了 Transformer 的实力。
(2)高鲁棒性、强泛化能力
Transformer 对于图像中的扰动以及遮挡等情况下,具备很强的鲁棒性和泛化性。
在自动驾驶感知识别中,经常会因雨雪天气、视觉遮挡以及重叠等原因,CNN 模型会出现错误的判断,Transformer 针对这类问题的处理则具有更好的性能。
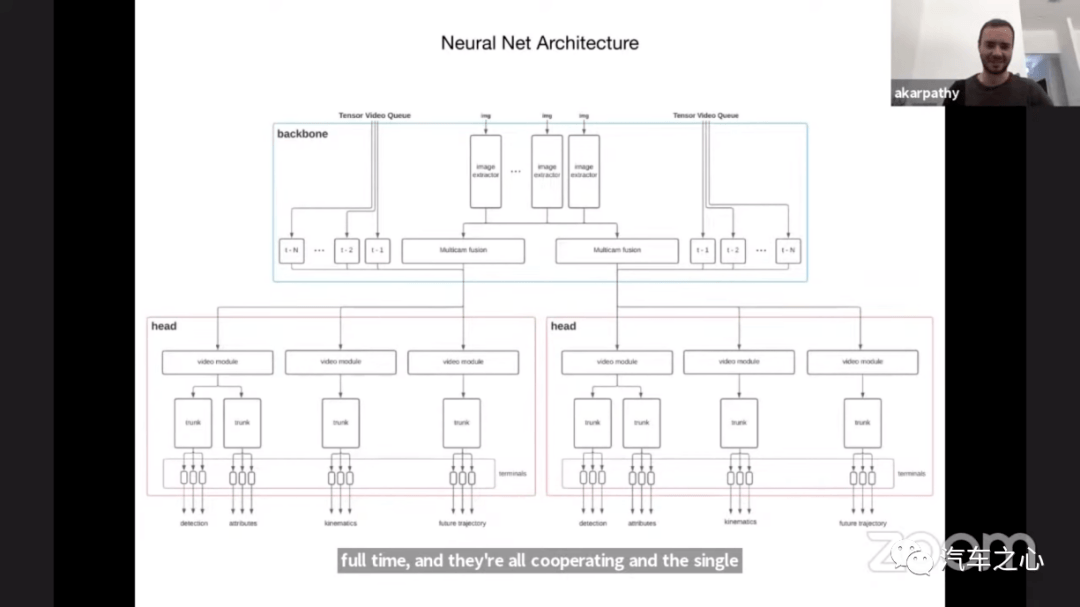
1、基于 Transformer 的特斯拉神经网络架构
在今年 CVPR 的 workshop 上,Andrej Karpathy 两次提到了 Transformer:
特斯拉从安装在汽车周围的八个摄像头的视频中用传统的 ResNet 提取图像特征,并使用 Transformer 算法将它们融合在一起。
Transformer 所具有的对像素位置关系的理解,顺理成章地被应用在图像的拼接上,形成全面的场景认知。
同时,特斯拉应用 Transformer、CNN、3D 卷积中的一种或者多种组合,去做跨时间的融合,基于 2D 图像形成具有景深的 3D 信息输出。
Transformer 可以很好地在空间-时序维度上进行建模。
Transformer 需要依托于大规模的数据集,同时大规模训练自然也需要巨大的算力。特斯拉为此专门构建了超级计算机 Dojo。
2、数据量的质变+算力的质变+Transformer ≈ 感知的一次飞跃
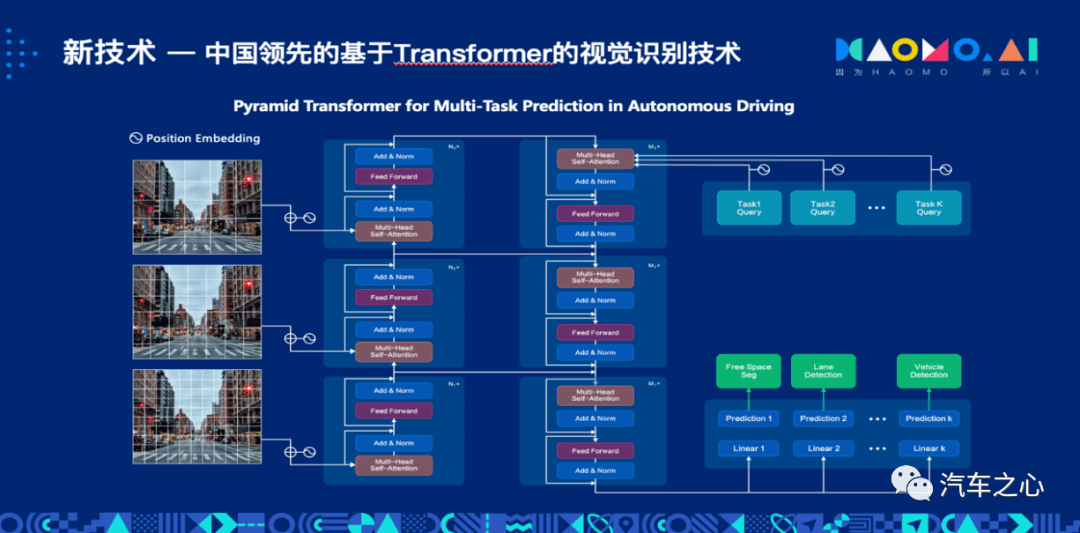
Transformer 不仅能处理各类视觉检测任务(车辆检测、VRU 检测、车道线检测、交通标志检测、红绿灯检测等),各类分割任务(可行驶区域检测、全景分析等),3D 点云的检测任务和分割(障碍物的检测等),还有潜力提升后续的规划和控制的相关技术。
更重要的是,Transformer 可以有效利用海量数据进行无监督的预训练。无监督学习,对算法提升至关重要。毕竟在海量的数据规模之下,数据标注等预处理的成本是非常高昂的。
特斯拉目前拥有 200 万辆级的量产车车队。毫末智行的前身是长城汽车的智能驾驶前瞻分部。脱胎于车企,毫末智行天生离量产更近。
从近期公开数据看,毫末智行 HWA 高速驾驶辅助系统已经批量装配长城汽车摩卡车型 5000 辆,预计 3 年内搭载 100 万辆长城汽车。
百万级的自动驾驶车辆,意味着每年数百亿级别的里程,一旦 Transformer 在如此大规模的数据中进行应用,对自动驾驶算法带来的突破可能会是颠覆性的。
新模型的使用甚至有可能推翻此前一些企业投入较早的「先发优势」,改变自动驾驶行业的秩序。
与特斯拉纯视觉方案不同的是,毫末智行包含激光雷达、毫米波雷达以及摄像头等异源传感器融合方案,目前该公司正在研究 Transformer 用于多种传感器信号输入的感知处理能力。
毫末智行相关负责人表示,「从视觉到雷达,甚至到下一轮的预测和规划,都可以用 Transformer 这个结构,Transformer 对于不同模态的数据具备优秀的适应能力,Transformer 之前做 NLP 的,现在都可以做视觉,它前端对于数据信号输入的模式,可以适应很多模式。」
「终极状态就是 Transformer 可以直接做到多模块的融合,也就是前端把视觉的输入,雷达的输入,都可以作为 Transformer 的输入,作为多模态的融合的模型,就是相当于直接从原信号到输出结果,中间是 Transformer,Transformer 在用它们的时候,它们就在早期的网络阶段就可以开始逐步融合。」
Transformer 技术的进一步应用,不仅为毫末智行在各条自动驾驶产品线上的视觉算法落地带来成倍的效率提升,还能够让各项视觉性能指标快速达到业内领先水平。
毫末智行凭借其「中国 Cruise」的发展模式优势,能够在短期内积累下大量的数据资源。
Transformer 的出现和数据的积累,让这家行业内的「后发企业」具备了弯道超车的机会。
数据量质变 + 算力质变 + Transformer = 感知智能上质的飞跃。
有新技术开道,中美自动驾驶也正进入全新的一轮较量。
来源:第一电动网
作者:汽车之心
本文地址:https://www.d1ev.com/kol/150972
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号