
特斯拉是一家很开放的车企。
所谓开放,指的是马斯克年初那一句「特斯拉愿意开放并共享自己的所有专利」,还有在 GitHub 上公开了自家车机操作系统的底层代码,以及在全球最大的软件 BUG 讨论社区 Bugcrowd 里面发下英雄帖,广邀全球黑客黑自家系统。


我们将这次演讲的精华部分摘录下来,并以尽量简练的语言解释,于是就有了今天的文章。
什么是 PyTorch?

电动星球注:BSD License 最早在1988 年由加州大学伯克利分校起草,是目前给予使用者最高自由的开源协议,使用者基本上可以「为所欲为」地修改源代码,并且将代码打包成专有软件。
至于 PyTorch,则是 Torch 使用 Python 语言编写的版本。
Torch 的底层是由 C 语言和 Lua 语言编写的,C 语言作为底层,而 Lua 语言作为深度学习库,两种语言都非常优秀,实际上目前仍然有很多大型企业采用 Torch 进行深度学习,比如上文提到的几家。
2017 年 1 月, PyTorch 正式在 GitHub 上发布,号称拥有更高的编译和运行效率,而实际上它也做到了——靠的就是 Python 语言。


特斯拉如何利用 PyTorch?
Andrej Karpathy 在演讲的开场这样说:「由于我们没有采用激光雷达,也没有采用高精度地图,所以 Autopilot 的一切功能,都依赖于来自车身四周 8 个摄像头提供原始图像之后,再进行的计算机视觉运算。」
他随后给出了一张流程图,里面是 Autopilot 工作的所有流程,有趣的是,Andrej Karpathy将这一套流程称为「Operation Vacation(操作假期)」,他说「因为现阶段我的团队已经可以在椅子上葛优瘫,然后数据就会从特斯拉的车子上传过来,在神经网络模型上自己不断循环运行」:
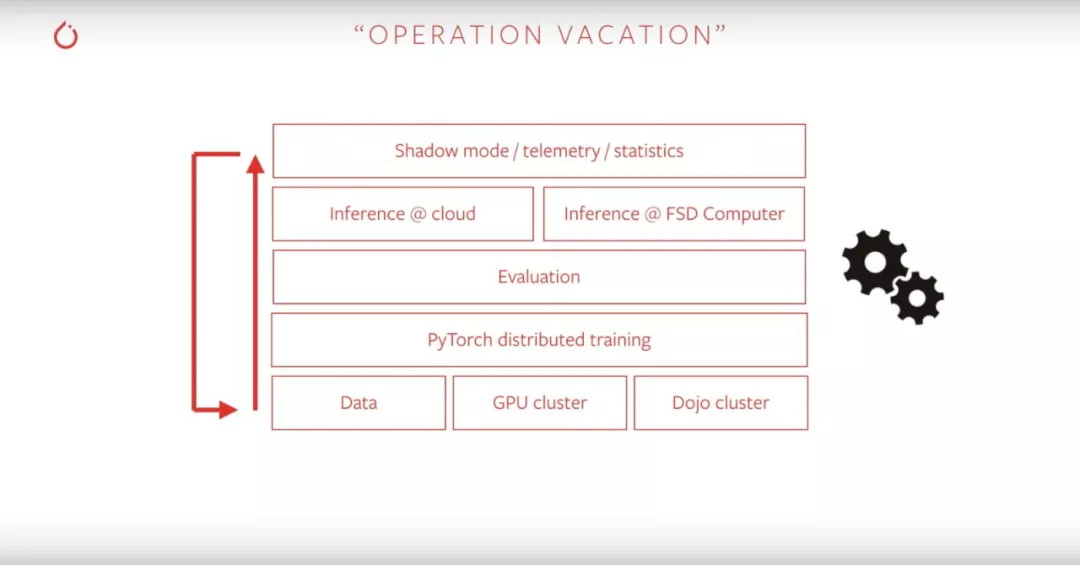
特斯拉AI部门令人艳羡的「假期」里面,「PyTorch Distributed Training」占了单独的一个部分——但凭什么呢?
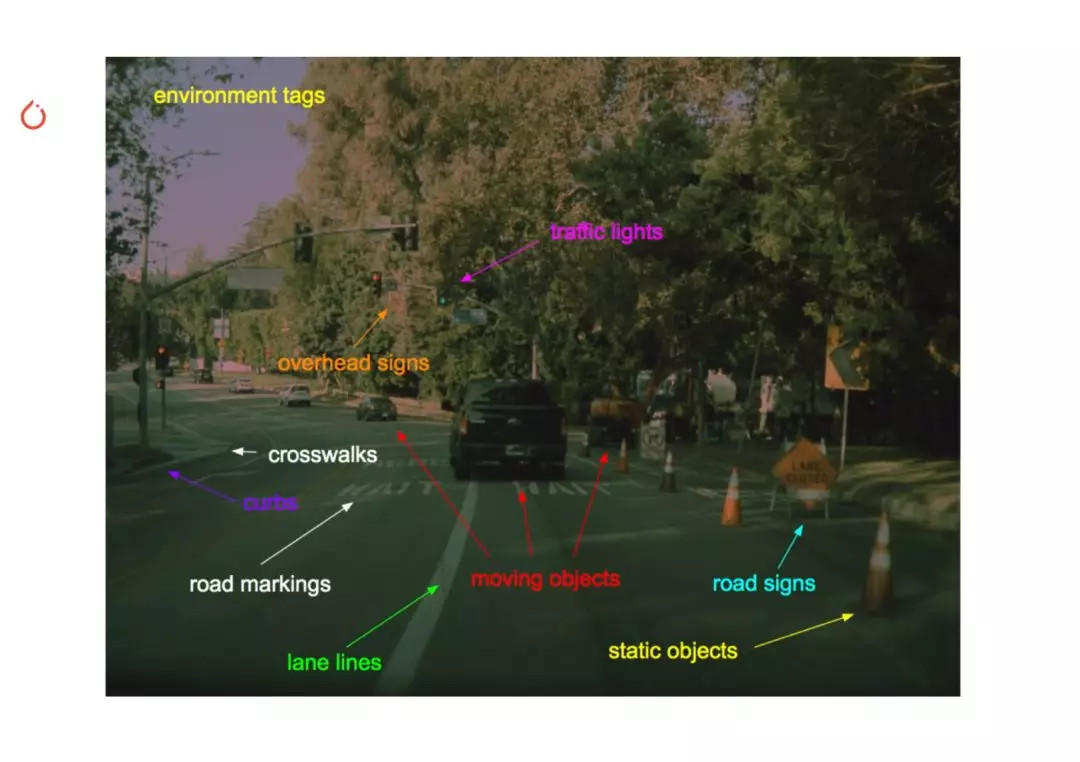
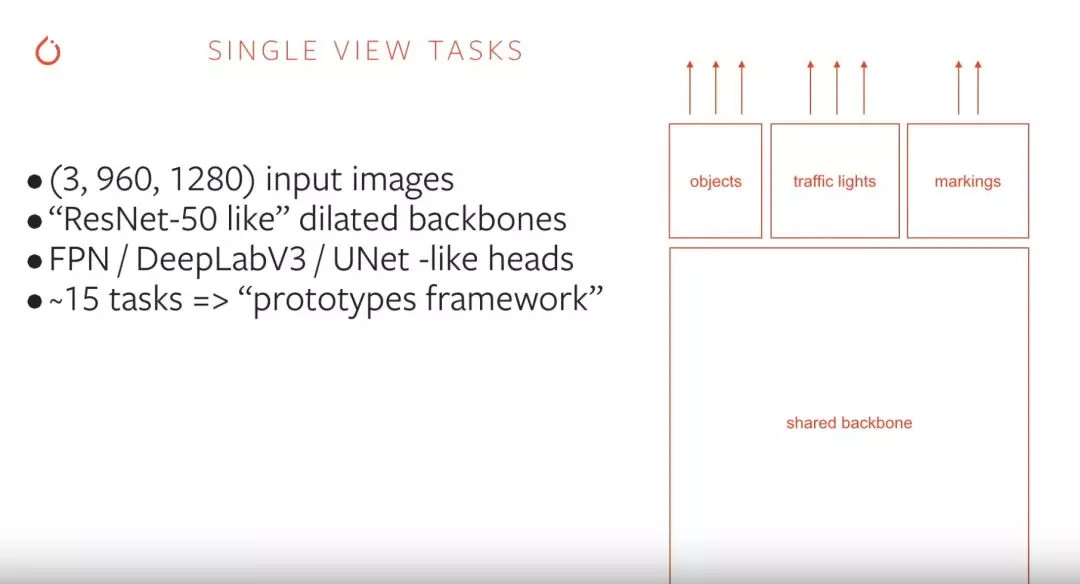
为了有效处理将近 100 个并行任务,特斯拉采用了「类 ResNet-50」的骨干网络。那什么是 ResNet-50?
随着深度学习研究的不断发展,深度学习神经网络也在不断加深,而随着网络深度的上升,训练准确度也会随之下降,ResNet 就是因此而生,它的中文名叫做深度残差网络。ResNet 有多个不同版本,包括 ResNet30/50/101 等,主要区分度在于 Layer 卷积层和 Block 区块数量上,这里就不展开了(毕竟是个汽车公众号…)。

还有 Smart Summon 模式下道路边缘的识别与确定:

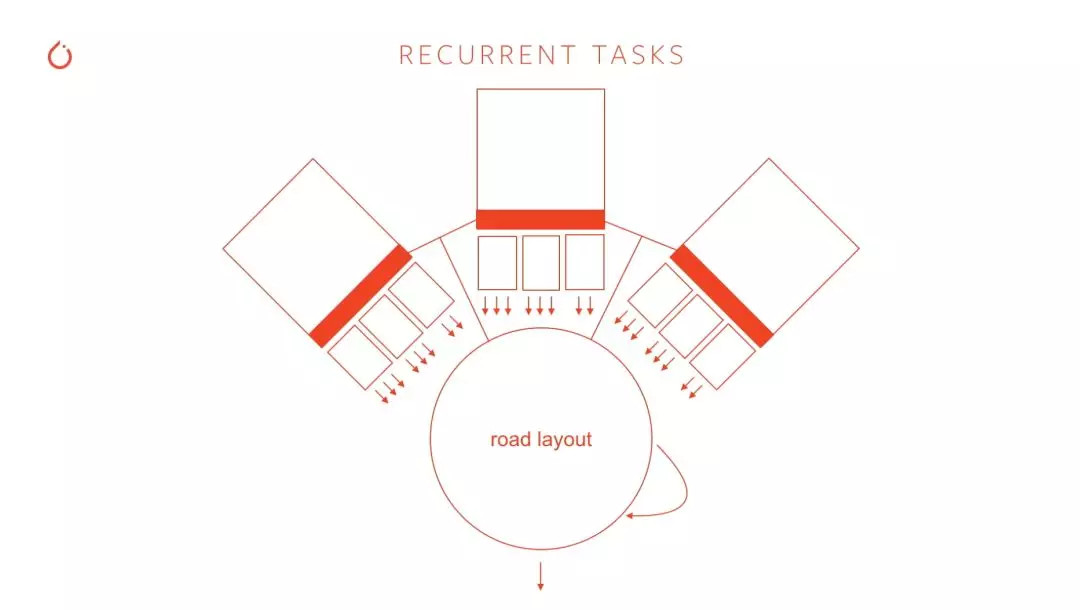
Recurrent Tasks 是来自于 RNN 的运算任务,中文名有两个,有的翻译成循环神经网络,更主流的译法是递归神经网络,因为 RNN 有两个算法变体——一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network),两者的缩写都是 RNN。

Andrej Karpathy 举了以上的场景做例子,解释 Recurrent Tasks 提升效率之后,对 Road Layout Prediction(道路层预测)的重要性:
「我们给每台摄像头都配备了相应的 Hydra Nets,但很多时候你需要同时采集多个摄像头的数据,然后再进行运算。比如说在过一个三岔路口的时候,我们有三个摄像头同时为这个场景的深度学习运算输入图像数据。此时的神经网络预测就不再只是单纯的图像识别,而是基于总-分结构的复合运算。」
谈到这个场景的时候,Andrej Karpathy 顺便以此为例子,对Hydra Nets给出了进一步的解释:

「我们为所有的计算任务准备了 8 个 HydraNets,当然所有 Hydra Nets 的运算任务都可以进一步进入 RNN 做递归运算。然后我们可以按照这样的总-分结构做输出。也就是说,Autopilot 软件里面有一个大型的单一计算网络,然后每一个任务都可以分采样这个计算网络(接收到的图像)的一小部分,然后训练那一小部分的神经网络。」
「比如说,我们可以单独训练摄像头的障碍物探测功能,或者是色彩深度网络,又或者是道路布局网络。所有单一任务都分采样了图像数据的一小部分,然后单独训练那一部分(的神经网络)」。

乍眼一看,这张图里面只有两个数字是可以望文生义的:代表原因的8个摄像头和代表结果的 4096 幅图像。而其中的过程则相当复杂。
Time steps 和 Batch size 需要一起讲,没有写中文是因为现在的深度学习界依然没有给它们一个比较信达雅的官方翻译。其中 Batch size 代表了在深度学习网络中单一批次的数据数量,比如我们往一个 RNN 里面输入 100 条数据,分成 10 个 Batch,那 Batch size 就是 10。
至于 Time steps 则是预测最终值需要的最大「步数」,比如说 Autopilot 软件的 Time steps 是 16,也就是说每次会生成 x0-x15,一共 16 组数据,最终预测结果——每次,指的就是图中每一个「Forward pass」。
目前深度学习最热门的硬件是 GPU,Andrej Karpathy 则用了一张图来描述 Autopilot 神经网络对于 GPU 运算的要求有多高:

在图中显示的 70000 GPU Hours,表示Autopilot深度计算网络如果用单一GPU运算需要用到 7 万小时——Andrej Karpathy 的原话是「如果你用一组 8 个 GPU 去训练 Autopilot 的深度运算网络,你得花一年」——当然他没说用作对比的是什么 GPU。
结语
今天 Andrej Karpathy 的演讲,虽然不太准确,但我们可以尝试用一句话概括——特斯拉很希望把你的车变成一个人。
今年 4 月份 FSD 芯片发布的时候,Andrej Karpathy 说过一句话,宣布了特斯拉与激光雷达彻底绝缘:「你会开车是因为你的眼睛看到了路况,而不是你的眼睛发射出激光」。今天,Andrej Karpathy 也说了「我们不用高精度地图」。
于是,一辆逐步走向自动驾驶的特斯拉,在行为模式上会变得越来越像人——用眼睛收集图像数据,然后用大脑判断自身所处环境,指挥四肢做出行动。
特斯拉的逻辑似乎更接近人类本能,但却是汽车界实打实的少数派。传统汽车界,包括造车新势力,都对激光雷达和高精度地图抱有更高的信心。
蟹老板上周体验小鹏 P7的时候说过这么一段话:
「超视距+实时在线,这是我们认为小鹏 P7 在自动驾驶方案上与特斯拉最大的不同。某种程度上,你可以将特斯拉看成桌面端或者单机的,将小鹏 P7 看成是移动端或者联网的。」
来源:第一电动网
作者:电动星球News蟹老板
本文地址:https://www.d1ev.com/kol/103446
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号