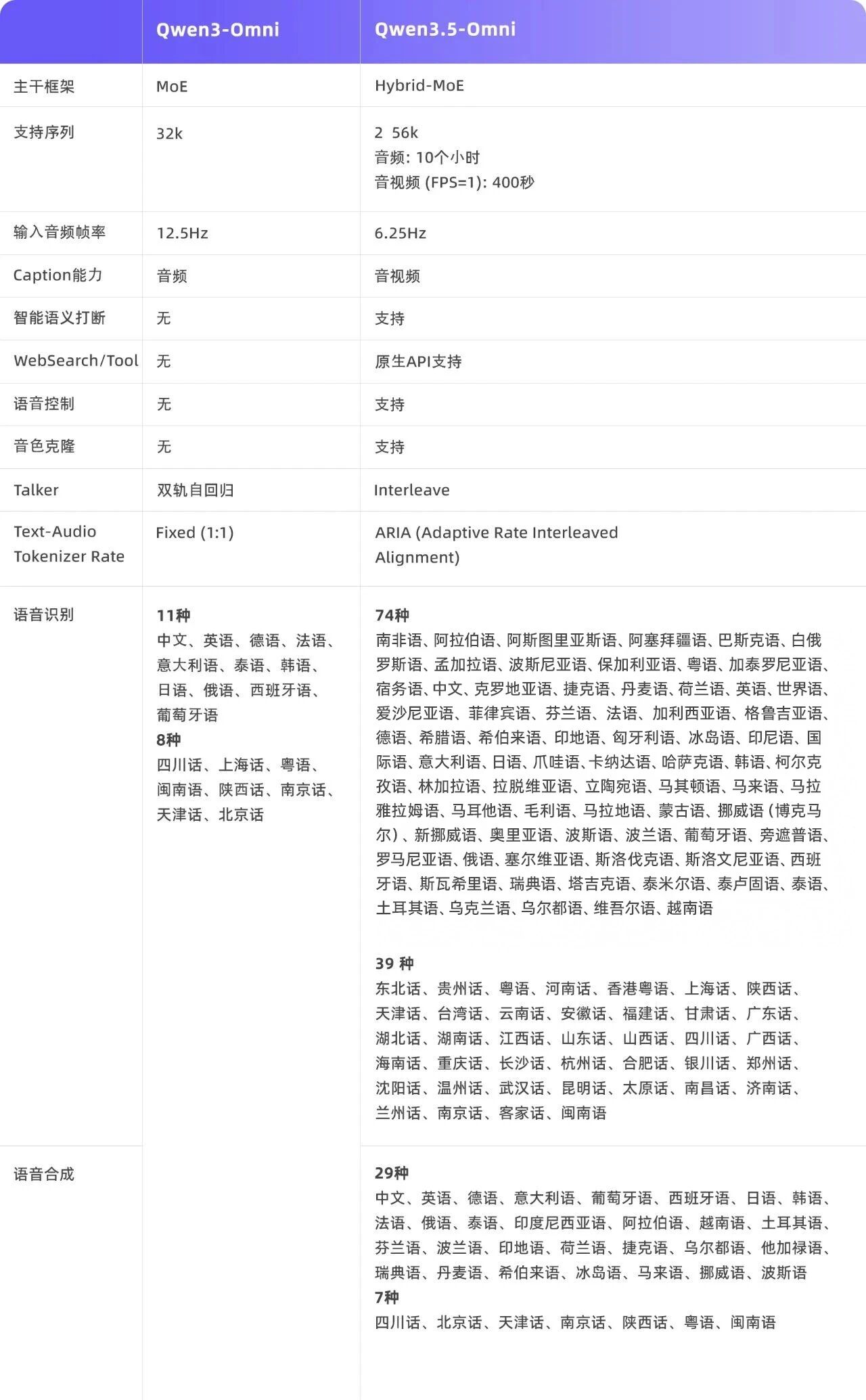
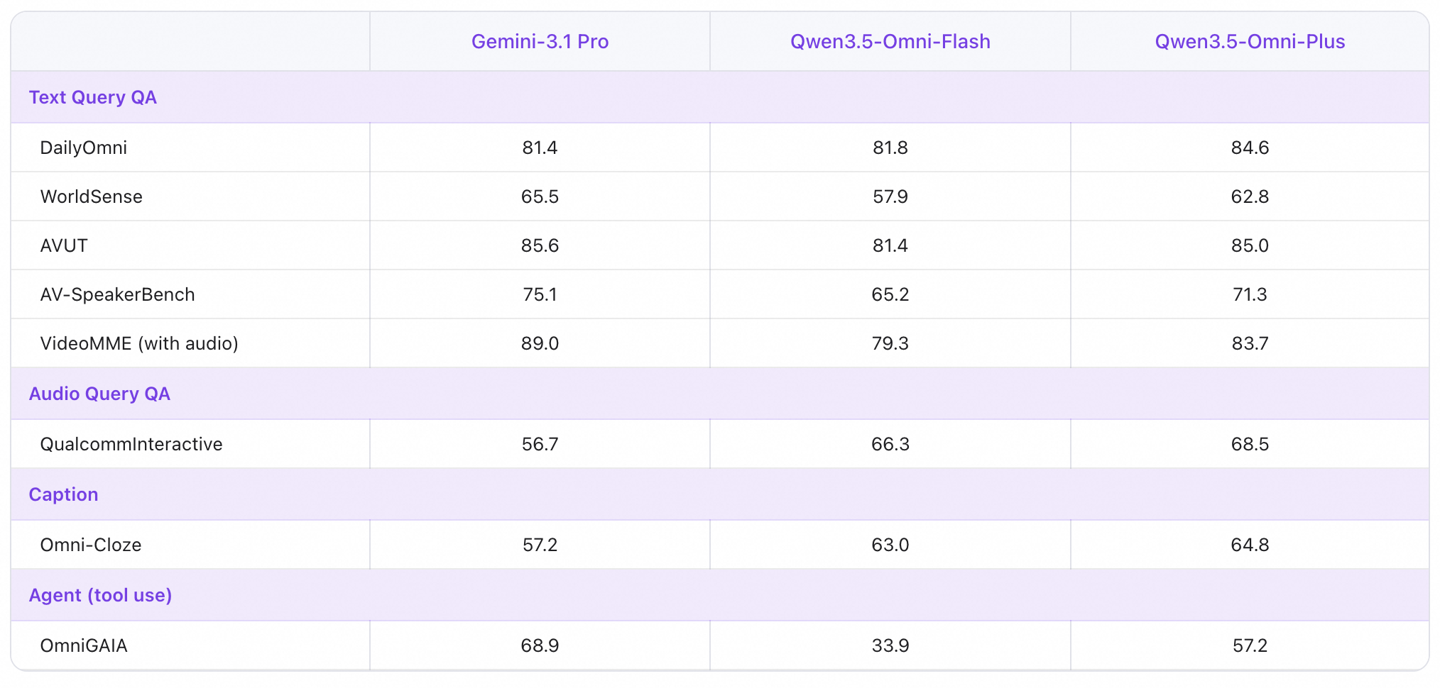
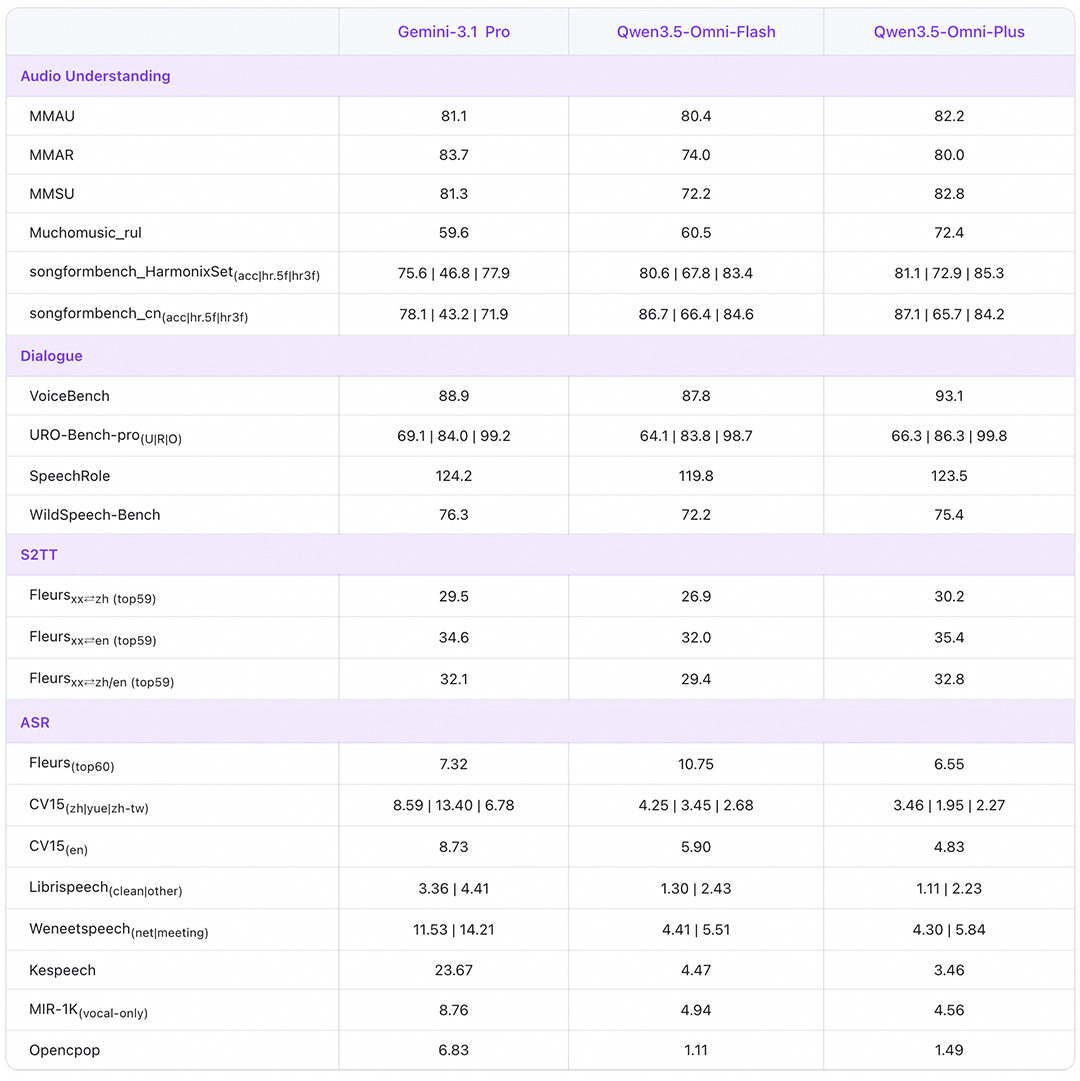
3月30日,阿里巴巴集团旗下的阿里千问发布了全新的全模态大模型Qwen3.5-Omni,该模型在多模态理解和生成能力上取得了显著进步。Qwen3.5-Omni能够无缝理解文本、图片、音频及音视频输入,并支持细粒度、带时间戳的音视频Caption生成。在音频及音视频分析、推理、对话、翻译等任务中,该模型以215项SOTA成绩超越了Gemini3.1-Pro,展现了其在自然语言处理领域的强大实力。
Qwen3.5-Omni具备Audio-VisualVibeCoding能力,能够根据画面逻辑生成Python代码或前端原型,这一能力在未进行专门训练的情况下自然涌现,为用户提供了从创意到实现的快速通道。此外,该模型支持语义打断、音色克隆及语音控制,使得对话体验更加自然,用户可以像与真人交流一样控制声音的大小、语速与情绪。
Qwen3.5-Omni还支持256K超长上下文与113种语言识别,能够处理长达10小时的音频或1小时的视频内容。它原生支持WebSearch和复杂FunctionCall,不仅能进行聊天,还能帮助用户完成实际任务,如根据用户指令生成网页内容和可运行的代码。用户可以通过阿里云百炼搜索Qwen3.5-Omni调用API,该模型提供了Plus、Flash、Light三种尺寸,以满足不同场景的需求。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号