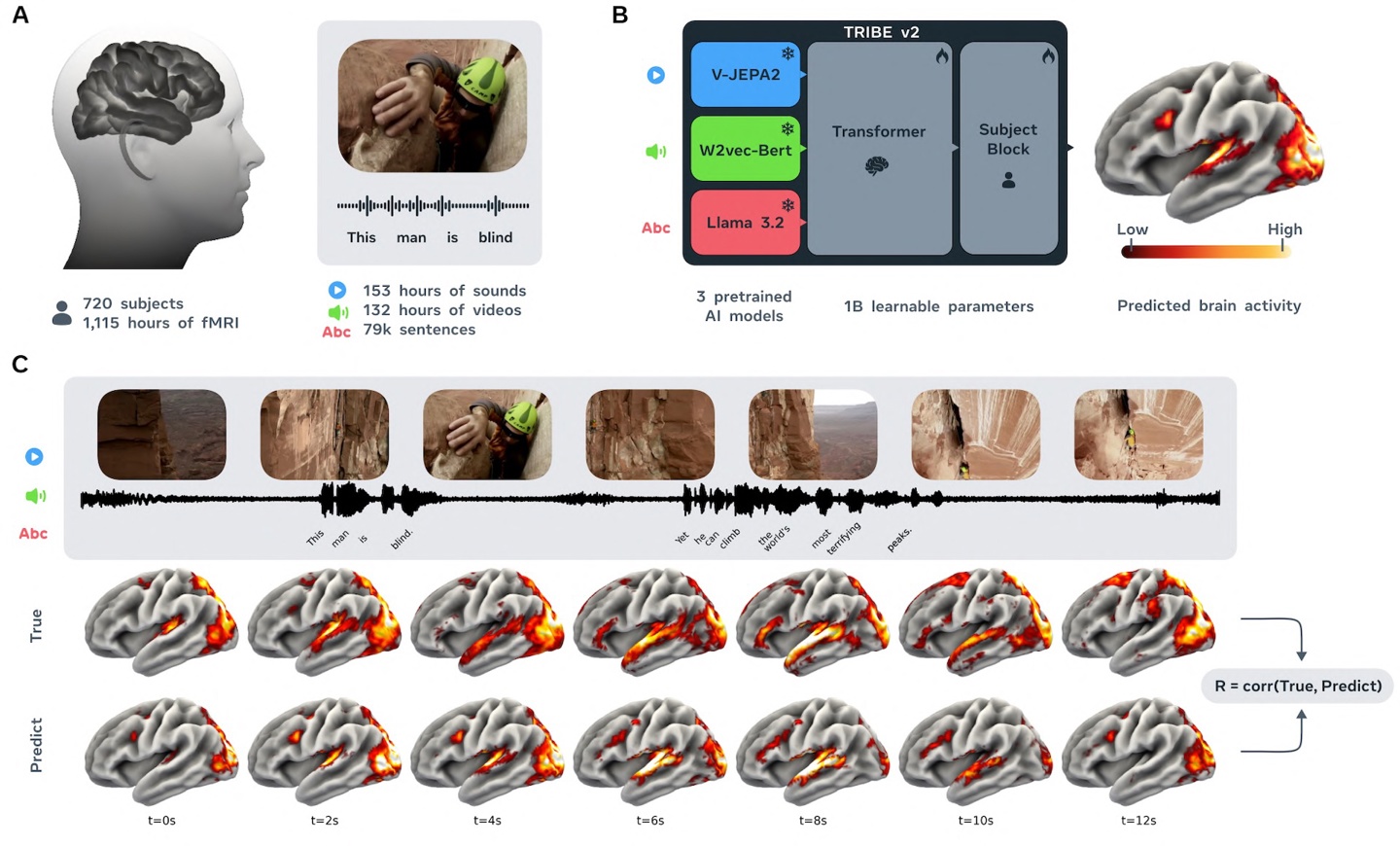
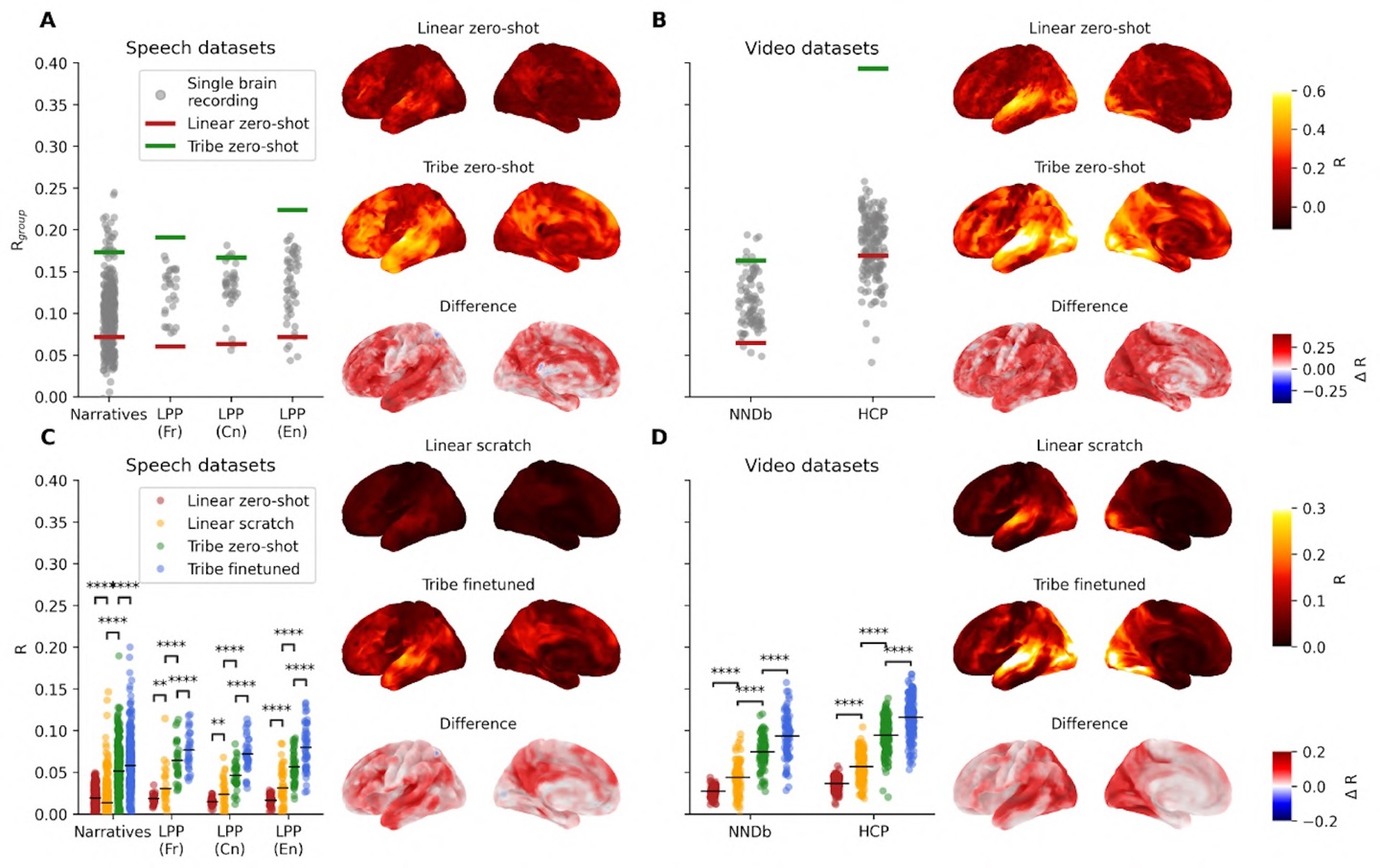
3月28日,科技媒体TheDecoder报道,Meta基础人工智能研究团队(FAIR)开源了一款名为TRIBEv2的全新AI模型,该模型能够精准预测人类大脑对图像、声音和文本的反应。TRIBEv2的核心优势在于无需实际测量即可预测大脑对视觉、听觉和语言刺激的反应,有望改变传统神经科学研究的局限性。模型通过三个预训练大模型提取特征,再由Transformer架构整合信息,输出包含7万个“体素”的大脑活动图。TRIBEv2在预测大脑活动方面表现出色,其预测结果比单人真实的脑扫描图更清晰,且准确度远超传统线性模型。
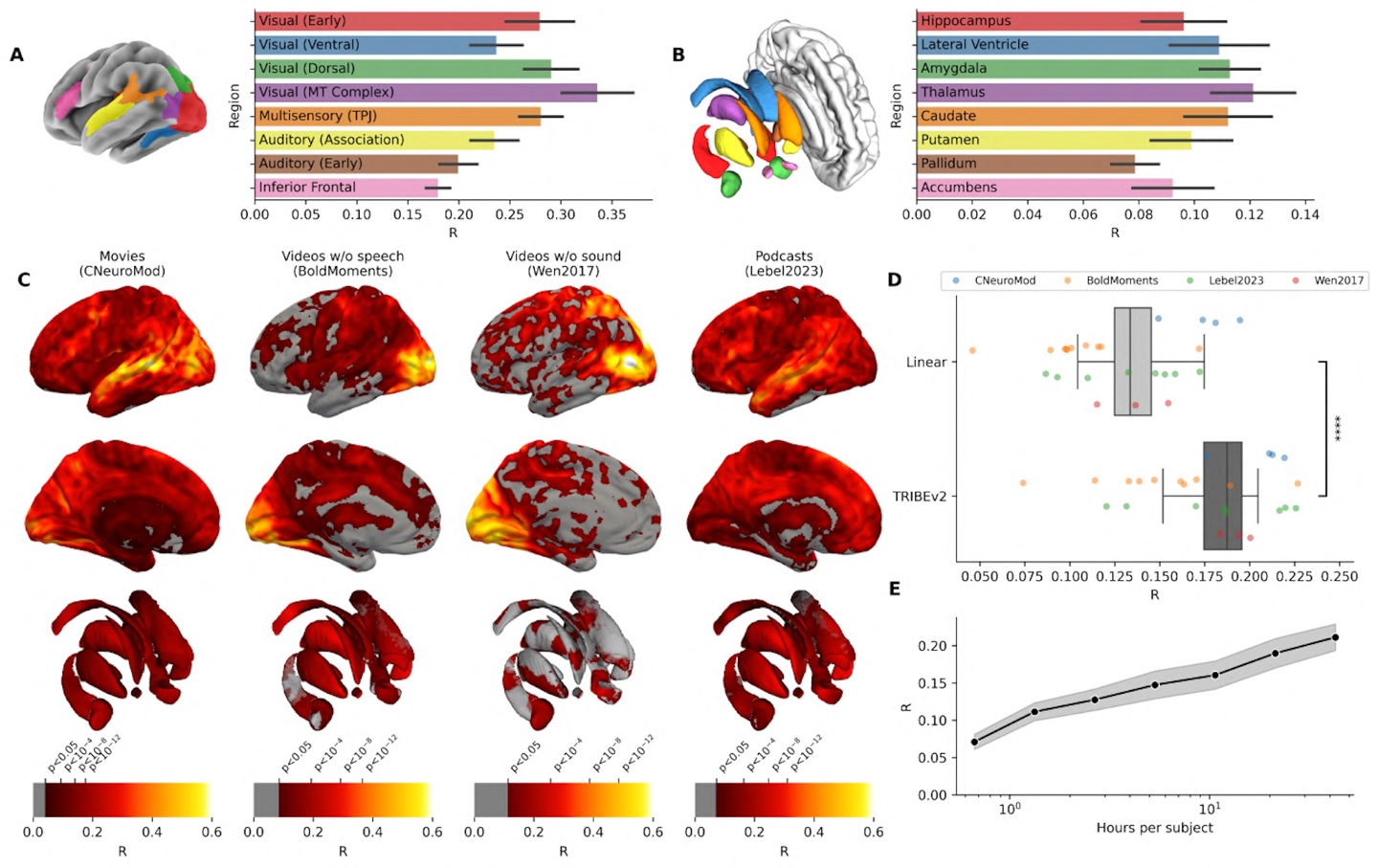
TRIBEv2模型揭示了不同感官如何激活特定的大脑区域,例如单独输入音频会激活听觉皮层,而多模态数据输入时,大脑颞叶、顶叶和枕叶交界处的预测准确率可提升50%。在视觉实验中,模型识别了面部、地点、身体和角色的专门大脑区域。尽管TRIBEv2表现出色,但它依赖存在数秒延迟的血流数据,无法捕捉毫秒级的神经动态,且缺乏触觉和嗅觉维度。
Meta已全面开源TRIBEv2模型的代码与权重,并计划探索其在规划脑科学实验、构建类脑AI架构及诊断脑部疾病等领域的应用潜力。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号