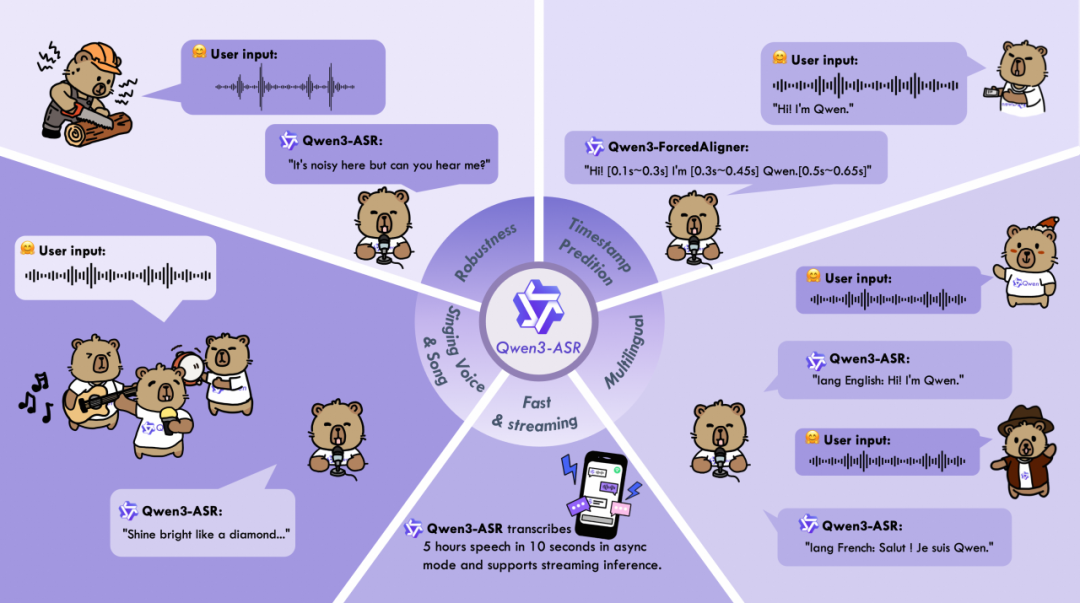
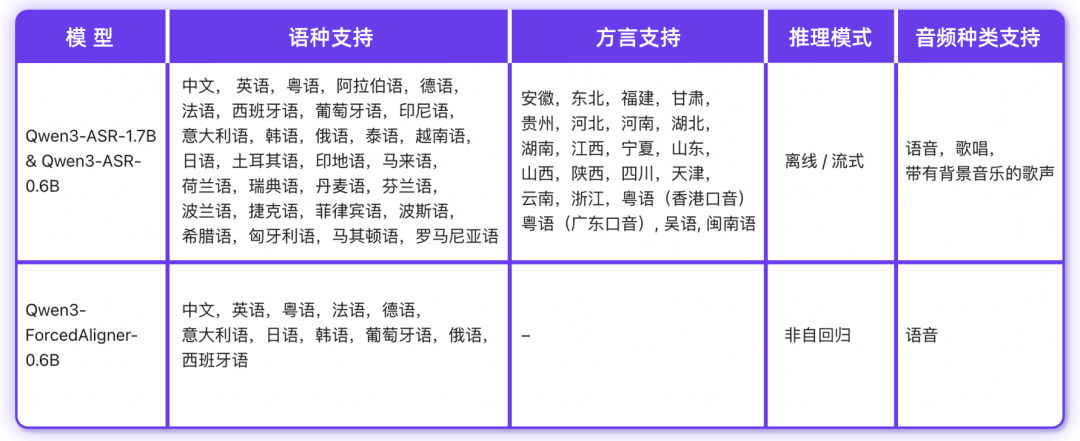
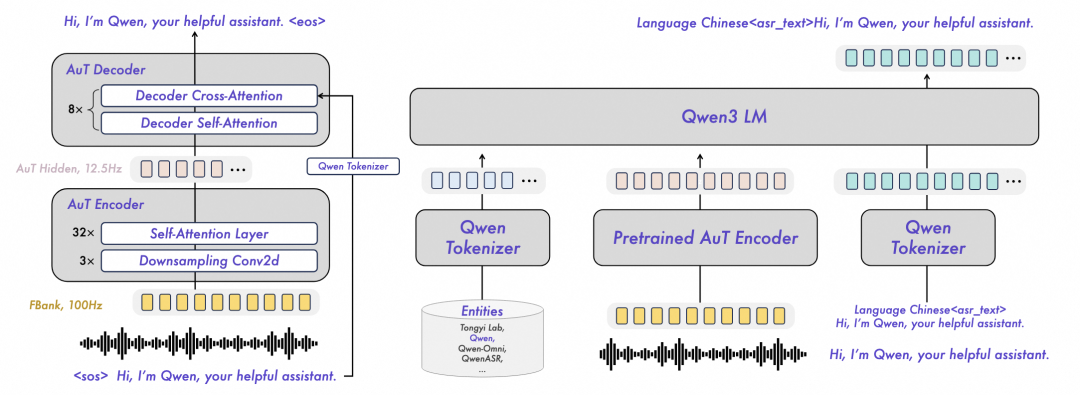
今日,阿里千问团队宣布开源Qwen3-ASR系列模型,这一系列包含两个语音识别模型Qwen3-ASR-1.7B与Qwen3-ASR-0.6B,以及一个语音强制对齐模型Qwen3-ForcedAligner-0.6B。这些模型支持52个语种与方言的识别,依托预训练AuT语音编码器和Qwen3-Omni基座模型,实现了精准稳定的语音识别。Qwen3-ASR-1.7B在中文、英文等场景下达到SOTA,具备复杂文本识别能力和强噪声下的稳定性;而0.6B模型则在性能与效率上取得均衡,128并发异步服务推理能实现2000倍吞吐,即10秒处理五小时音频。
Qwen3-ASR系列模型的核心特性包括All-in-one支持多语种识别、准确快速的语音识别能力、流式/非流式一体化推理,以及独创的强制对齐模型。这些模型在中文/英文、多语种、中文方言、歌声识别及复杂声学与语言场景下进行了系统评估,显示出在多个维度的公开与内部基准上取得SOTA。此外,Qwen3-ForcedAligner-0.6B模型支持11个语种的高精度强制对齐,时间戳预测精度超越传统模型,单并发推理RTF达到0.0089。阿里千问团队希望Qwen3-ASR系列模型的开源能推动语音识别与理解的研究与发展,并将提供模型结构、权重及推理框架的开源。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号