11月25日,腾讯混元宣布推出全新开源模型HunyuanOCR,参数规模为1B,基于混元原生多模态架构设计,多项OCR应用榜单达到SOTA(最先进水平)成绩。HunyuanOCR模型采用全端到端范式,通过规模化应用导向数据和在线强化学习,展现出稳健的端到端推理能力。
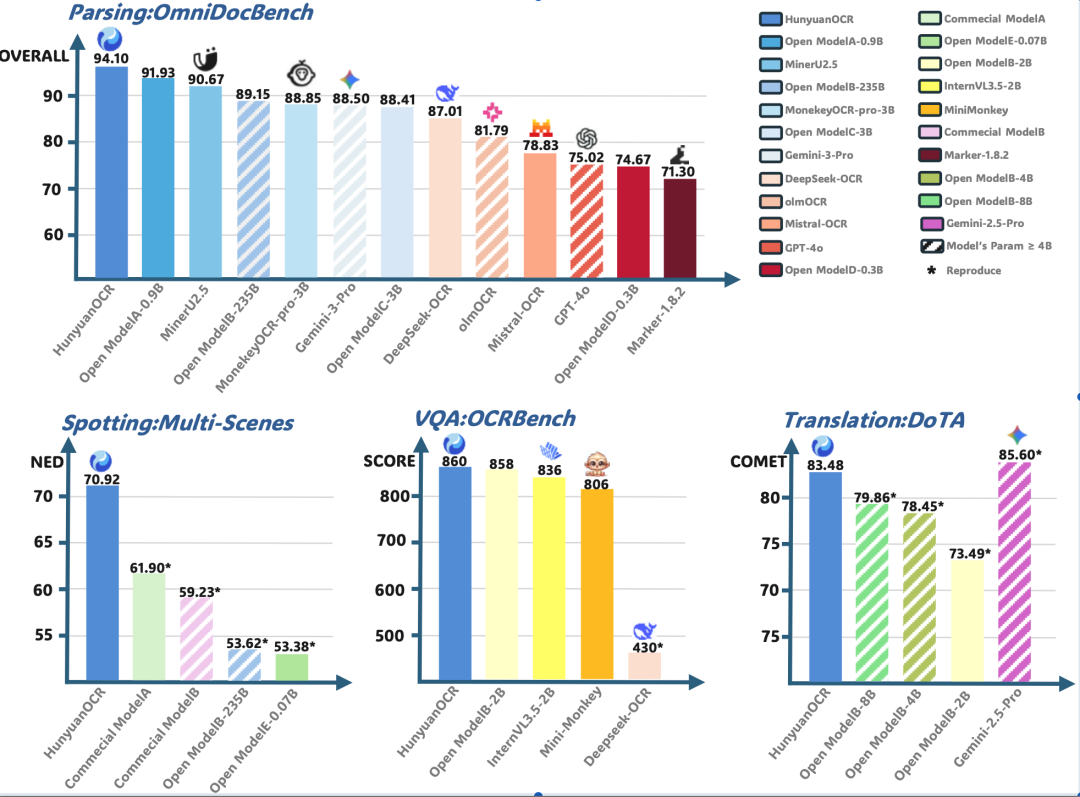
HunyuanOCR由原生分辨率视频编码器、自适应视觉适配器和轻量化混元语言模型三大部分构成。在复杂文档解析的OmniDocBench测评中,HunyuanOCR以94.1分的成绩超越
谷歌Gemini3-pro等领先模型。在自建的覆盖9大应用场景的基准上,HunyuanOCR在文字检测和识别能力上大幅度领先同类开源模型及商业OCR模型。在OCRBench榜单上,HunyuanOCR以1B总参数的配置取得3B以下参数模型的SOTA成绩。
HunyuanOCR支持多语种复杂文档解析,具备文字检测和识别能力,应用于票据字段抽取、视频字幕识别、拍照翻译等场景。模型对文档、艺术字、街景、手写、广告、票据、截屏、游戏、视频等场景表现卓越。此外,HunyuanOCR支持14种高频小语种翻译,包括德语、西班牙语等,取得ICDAR2025端到端文档翻译比赛小模型赛道冠军。


来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号