神经网络是一种机器学习模型,广泛用于机器人目标识别、自然语言处理、药物开发、医学成像和驱动无人驾驶汽车等任务。使用光学现象加速计算的新型光学神经网络可以比其他电子对应物更快、更有效地运行。
但随着传统神经网络和光学神经网络越来越复杂,它们消耗了大量的能量。为了解决这个问题,研究人员和包括谷歌、IBM和特斯拉在内的主要科技公司开发了“人工智能加速器”,这是一种专门的芯片,可以提高培训和测试神经网络的速度和效率。
对于电子芯片,包括大多数人工智能加速器,有一个理论上的最低能耗限制。最近,MIT的研究人员开始为光神经网络开发光子加速器。这些芯片执行数量级的效率更高,但它们依赖于一些体积庞大的光学元件,这些元件限制了它们在相对较小的神经网络中的使用。
在《物理评论X》上发表的一篇论文中,MIT的研究人员描述了一种新型光子加速器,它使用更紧凑的光学元件和光信号处理技术,以大幅降低功耗和芯片面积。这使得芯片可以扩展到神经网络,比对应的芯片大几个数量级。
比传统电子加速器的能耗极限低1000万倍以上
神经网络在MNIST图像分类数据集上的模拟训练表明,加速器理论上可以处理神经网络,比传统电子加速器的能耗极限低1000万倍以上,比光子加速器的能耗极限低1000倍左右。研究人员现在正在研制一种原型芯片来实验证明这一结果。
“人们正在寻找一种能够计算出超出基本能耗极限的技术,”电子研究实验室的博士后Ryan Hamerly说:“光子加速器是很有前途的……但我们的动机是建造一个(光子加速器)可以扩展到大型神经网络。”
这些技术的实际应用包括降低数据中心的能耗。“对于运行大型神经网络的数据中心的需求越来越大,而且随着需求的增长,它越来越难以计算,”合著者、电子研究实验室的研究生Alexander Sludds说,其目的是“利用神经网络硬件满足计算需求……以解决能源消耗和延迟的瓶颈”。
与Sludds和Hamerly合写该论文的有:RLE研究生、联合作者Liane Bernstein;麻省理工学院物理教授Marin Soljacic;一名麻省理工学院电气工程和计算机科学副教授Dirk Englund;一名RLE的研究员,以及量子光子学实验室的负责人。
依赖于一种更紧凑、节能的“光电”方案
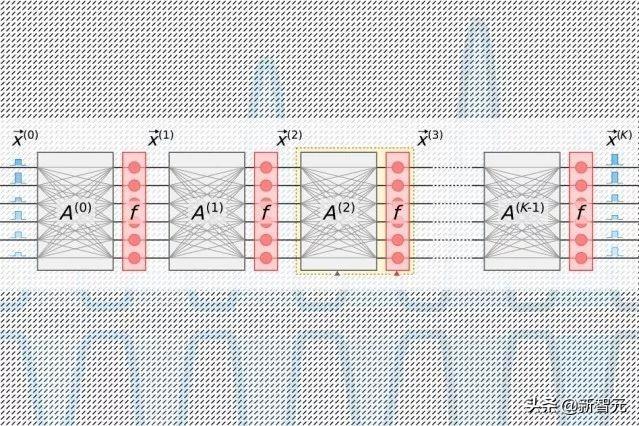
神经网络通过许多包含互联节点(称为“神经元”)的计算层来处理数据,从而在数据中找到模式。神经元接收来自其上游“邻居”的输入,并计算一个输出信号,该信号被发送到下游更远的神经元。每个输入也被分配一个“权重”,一个基于其对所有其他输入的相对重要性的值。随着数据在各层中“深入”传播,网络逐渐学习更复杂的信息。最后,输出层根据整个层的计算生成预测。
所有人工智能加速器的目标都是减少在神经网络中的特定线性代数步骤(称为“矩阵乘法”)中处理和移动数据所需的能量。在那里,神经元和权重被编码成单独的行和列表,然后结合起来计算输出。
在传统的光子加速器中,脉冲激光编码了一个层中每个神经元的信息,然后流入波导并通过分束器。产生的光信号被送入一个称为“Mach-Zehnder 干涉仪”的正方形光学元件网格中,该网格被编程为执行矩阵乘法。干涉仪用每个重量的信息进行编码,使用处理光信号和重量值的信号干扰技术来计算每个神经元的输出。但是有一个缩放问题:对于每个神经元,必须有一个波导管,对于每个重量,必须有一个干涉仪。由于重量的数量与神经元的数量成正比,那些干涉仪占用了大量的空间。
“你很快就会意识到输入神经元的数量永远不会超过100个左右,因为你不能在芯片上安装那么多的元件,”Hamerly说,“如果你的光子加速器不能每层处理100个以上的神经元,那么很难将大型神经网络应用到这种结构中。”
研究人员的芯片依赖于一种更紧凑、节能的“光电”方案,该方案利用光信号对数据进行编码,但使用“平衡零差检测”进行矩阵乘法。这是一种在计算两个光信号的振幅(波高)的乘积后产生可测量电信号的技术。
光脉冲编码的信息输入和输出神经元的每个神经网络层——用来训练网络——通过一个单一的通道流动。用矩阵乘法表中整行权重信息编码的单独脉冲通过单独的通道流动。将神经元和重量数据传送到零差光电探测器网格的光信号。光电探测器利用信号的振幅来计算每个神经元的输出值。每个检测器将每个神经元的电输出信号输入一个调制器,该调制器将信号转换回光脉冲。光信号成为下一层的输入,以此类推。
这种设计只需要每个输入和输出神经元一个通道,并且只需要和神经元一样多的零差光电探测器,而不需要重量。因为神经元的数量总是远远少于重量,这就节省了大量的空间,所以芯片能够扩展到每层神经元数量超过一百万的神经网络。
找到最佳
有了光子加速器,信号中会有不可避免的噪声。注入芯片的光线越多,噪音越小,精确度也越高——但这会变得非常低效。输入光越少,效率越高,但会对神经网络的性能产生负面影响。但是有一个“最佳点”,Bernstein说,它在保持准确度的同时使用最小的光功率
人工智能加速器的最佳位置是以执行一次两个数相乘的单一操作(如矩阵相乘)需要多少焦耳来衡量的。现在,传统的加速器是用皮焦(picojoules)或万亿焦耳(joule)来测量的。光子加速器以attojoules测量,效率高出一百万倍。
在模拟中,研究人员发现他们的光子加速器可以以低于attojoules的效率运行。 “在失去准确性之前,你可以发送一些最小的光功率。我们的芯片的基本限制比传统的加速器低得多......并且低于其他光子加速器,”Bernstein表示。
来源:新智元
本文地址:https://www.d1ev.com/news/jishu/92635
以上内容转载自新智元,目的在于传播更多信息,如有侵仅请联系admin#d1ev.com(#替换成@)删除,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号