在智能驾驶中,汽车需要通过在感知、规划、决策、控制方面的努力,让机器具备“智力”。人们通常愿意把这一个过程,称之为人工智能。而事实上,所谓的智能只是一个结果,想要让机械具备智能,过程当中需要无数人力劳动的堆砌。
数据标注就是这样一个工作,它存在的意义便是让机器理解、认识世界。通常的数据标注,一般有语音、文本、图像等类型,工作人员需要更具行业的标准或者客户要求,对相应的数据进行分类、画框、注释、标记等等,然后将结果数据反馈给客户。客户依此来训练机器对上述特征的认识,C端用户所体验到的智能语音交互、视觉图像识别等都因此而来。
数据标注是一个重人工的工作,需要大量人员做简单重复的工作,成本高昂,业内也在寻求一种自动化的方式。
业内人士告诉《高工智能汽车》,自动化数据标注在目前的行业内还属于一个”遥远的梦”,在可预见的时期内,数据标注还将以人为主。
数据标注分类
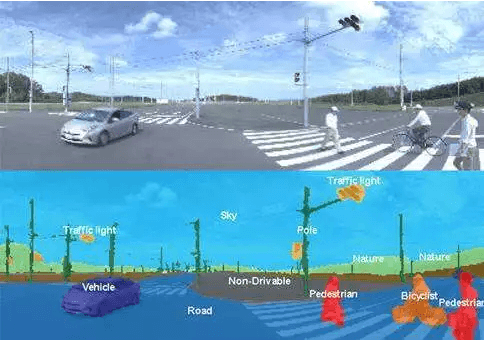
数据标注的对象通常有图像、语音、文本、视频、雷达等。图像类主要针对视觉识别类公司,所要标注的图像内容包括人像、建筑物、植物、道路、交通标志、车辆等,每项内容下面,又会根据不同的特征进行不同标签的标注。
以应用最广的人像为例,标注公司可能需要对目标的性别、年龄、肤色、着装、表情、发型、姿态做出标志,方式会是画框、打标签等。
语音标注也是常见的一种,公司会将音频的文字对照写出,同时也可能会将语句中的主谓宾标出,方便机器学习。
随着激光雷达在自动驾驶中频繁的应用,雷达对障碍物扫描识别的需求也愈加频繁,而如何让激光雷达扫描到的物体通过更直观的形式显示给用户,也成了要完成的工作。
数据标注公司会将激光雷达扫描出的物体大概,进行更精细的物体轮廓勾勒,同时也会对相应障碍物进行标识,包括但不限于名称、类别,以及通过不同颜色进行展示。通过这种深度处理后,激光雷达也就间接具备了识别障碍物的能力。
无论图像、语音还是雷达数据的标注,通常数据标注公司会有一套自己的标准,对数据进行分类,而目标客户也会有自己的标注。
业内人士表示,一般而言,客户会有自己的需求,公司依规而行。目前在国内,阿里巴巴、腾讯、百度等大型互联网公司,拥有海量的数据标注需求,单个订单量都是以亿元为单位。如此大的订单,基本都是分包给不同的数据标注公司进行处理,国内外还没有一家公司能够处理这样大的订单。
另外还有自动驾驶公司,以及视觉图像处理的公司,也有着数据标注的强烈的需求,他们需要用标注后的数据来训练人工智能,而人工智能的日趋成熟,是永无止境的。
劳动密集型产业
面对数据标注的巨大需求,整个行业的技术水平如何?在回答这个问题之前,首先给大家罗列一组数据。
ImageNet 是一个计算机视觉系统识别项目名称,是由美国斯坦福的计算机科学家李飞飞教授领衔的团队模拟人类的识别系统建立的,它是目前世界上图像识别最大的数据库——1,500 万张标注图片的数据集,这是来自 167 个国家的 48,940 名工作者,花费了 2 年时间,清理、分类、标记了近十亿张通过互联网搜集到的图片,才得到的。
由于数据庞大又开源,ImageNet 很快成为成为研究图像识别的首选。但尽管如此, ImageNet 也有自己的弱点:标注框太大、标注方式少和不时出现的错误,使它难以被用来训练实际应用的算法模型。
从以上可以看出,即使是业内最强大的图像识别库,数据标注都是通过人工完成的。因此,其它宣传数据标注自动化的,可信度较低。
业内人士透露,数据标注是一个简单又困难的事情。简单之处在于,确定了筛选规则以后,操作人员只需依规操作即可,没有执行上的难度,而困难之处在于,数据标注本质上是要获得更准确,更精细化的数据结果,高质量的数据是业内急需的。
但数据标注本身是一项枯燥的工作,工作人员需要对大量数据不断进行重复劳动,数据的一致性很难保证。
而这些数据标注的工作,本身是为了提升机器学习的能力,因此这部分工作只能由人来完成,人与机器之间的鸿沟,正是机器要跨越的。
数据标注公司目前的做法,是雇佣部分专业的标注人员,然后再外聘一些兼职的人员,共同完成订单。由于人工成本高昂,大部分数据标注公司,都将公司设在了三线以下的城市。
专业人员跟兼职人员的工作能力,还是存在一定的差距的。为了保证数据标注的质量,通常数据标注公司还会设立审核团队,对标注后的数据进行把关。
数据的采集、标注都是专业性很强的工作,必须有针对性的对每个素材进行专业指导。培训的过程包括了解目标 - 学习规则 - 线上培训&录像学习 - 实际场景练习 - 达标考试 - 进行工作 - 纠错讲解&改错(如果错误严重、产出不达标会打回规则学习阶段)。审核方面公司会采用多重交叉审核审核机制进行标注与审核,严格把控标注的每一道流程 。
业内人士表示,进行数据标注的人力成本还是较高,以语音数据为例,客户通常会提供完整有效的数据音频,然后以完成的有效时间段计量价格。
音频通常会包含方言,杂音等,标注人员有时需要反复听音频,才能完成音频转文字的工作。一小时的音频,常常需要一天才能完成,业内给出的价格通常在300元左右。
这个市场完全是自由市场,甲乙双方一方面要兼顾成本、质量等因素,另一方面也要考虑到人力成本,由于技术含量低,上升空间小,做数据标注工作的大部分都是短期工,从业人员积极性低,面临较大的人才流失问题。资本市场的博弈,最终要找到一个平衡点,让工人愿意留下来继续工作。
众包下的半自动化
资本逐利,为了降成本,提效率,无论数据标注公司还是客户,都在想办法提升数据标注的效率。
人们谈到更多的便是数据标注自动化,但业内人士表示,数据标注自动化是一个伪命题,除却技术可行性,完成自动化所需要的人才,在业内都属凤毛麟角。
本质上而言,大公司是最有实力做这部分工作的,但现实是大公司的数据标注业务,基本都外包给了小工司来做。而小公司,则还沉浸在人海战术中。
数据标注公司要提高标注的效率,以及降低成本,目前所努力的方向基本是众包、半自动化。所谓的众包,类似于国外高精地图的采集,即公司将订单发放到网上,让拥有闲暇时间的网友来合力完成数据标注的工作,中间可能会涉及到给予一些奖励,但相比现在的线下重劳力模式,已经减轻了不少成本。
但众包的形式,对数据标注的工作流程,有了更高的要求。网络用户完成数据标注,一定要简单,快速,容易上手,由此才能普及。目前的数据标注过程,需要人工画框,打标签,还需要后续的人工审核,整个流程较为复杂。
业内人士表示,现在能提高效率的工作,便是开发一套网上系统,将标注工作简单化、标准化,为标注人员尽量减少一些重复简单的工作。
开发这样一套系统,需要专业的研发人员,而大部分数据标注公司,鲜少拥有余力来进行这一部分纯粹投入、研发。因此,数据标注公司未来的目标是能够实现半自动化的数据标注,而这背后,还仍然要依靠众包。
所谓的自动化标注,本身是一个伪命题,如果数据都能通过自动化标注了,那本质上已经不需要标注了,因为人工智能已经有了如人一般的识别能力。而这一天什么时候会到来?众所期待~
来源:高工智能汽车
本文地址:https://www.d1ev.com/news/jishu/68881
以上内容转载自高工智能汽车,目的在于传播更多信息,如有侵仅请联系admin#d1ev.com(#替换成@)删除,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号