特约作者 / 周彦武(业内资深专家)
编辑 / 汽车之心
特斯拉最新的自动驾驶大脑 FSD,不惜血本用上了GDDR6。
如上图中的 D9ZPR,正反两面各用了 8 颗,总计16 颗,每颗容量 2GB。
但最近 ChatGPT 带动 GDDR6 需求暴增,价格略有上涨,目前每片价格大约10-13 美元。
实际上,特斯拉 HW4.0 的座舱控制器里还有 4 颗 GDDR6,每颗容量也是 2GB,合计 40GB 即200 美元以上。
大部分厂家都选择 LPDDR4 或 LPDDR5。
例如英伟达的中配 Orin 开发盒子是 4 颗 8GB 即 32GB 的 LPDDR5,只需要大约 50-60 美元,这与特斯拉 HW 4.0 中的第二代 FSD 价格相差 150 美元。
特斯拉 HW3.0 使用的是 8 片 2GB 的 LPDDR4,每片大约 3.5 美元,8 片只有28 美元。
当然,这当中最大赢家是美光,车载领域80%的 DRAM 市场均来自美光。美光是美国唯一存储器公司,也是除英特尔外美国本土几乎唯一的硬科技公司(AMD 的制造均由台积电完成)。
总体来看,车载领域目前都是使用 LPDDR,特斯拉再次开创先河:首次在车载领域使用GDDR。
01、什么是内存?
在细说 GDDR 前,我们先来了解内存的概念。
运算系统有两种存储:
一种是断电后存储内容不丢失的非易失性存储器(英语:Non-Volatile Memory,缩写:NVM),最常见的 NVM 是Flash 存储器;
还有一种是断电后存储内容就消失的易失性存储器,即 RAM。
RAM 又分为两类:
DRAM(Dynamic Random Access Memory,动态随机存取记忆体);
SRAM(Static Random Access Memory,静态随机存取记忆体)。
通常内存指的是 RAM,准确地说应该叫缓存或暂存。
NVM 原理类似电容,因此其读出写入速度很慢,跟 CPU 速度比差太多。为了 NVM 和 CPU 两者协调工作,加入内存做中转缓冲,可以说,RAM 计算单元与数据或指令存储之间的桥梁。
对于 AI 加速器来说,内存尤为重要。
所谓 AI 运算,就是矩阵乘积累加,输入矩阵与权重矩阵之间的乘积累加,需要频繁地读取权重矩阵或者说训练好的模型参数。
模型参数越大,自然就需要更高的带宽,一次性读出更多的参数。
小模型的鲁棒性和可移植性很差,因此人类 AI 的发展方向就是越来越大的模型,参数越来越多。
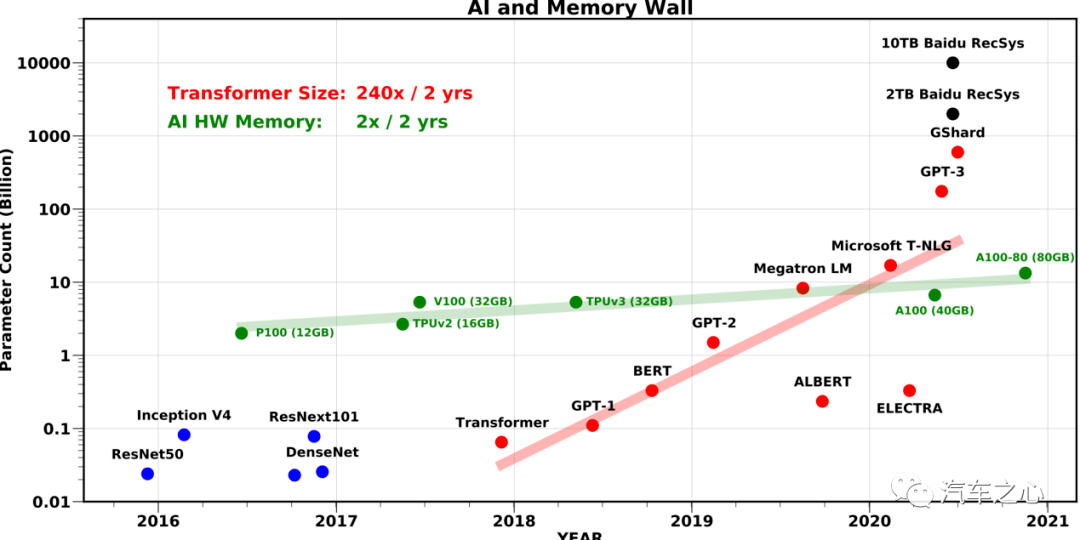
机器视觉的奠基者 ResNet 50 是 2500 万个参数,自动驾驶领域目前正火的 Transformer 在 9 千万到 3.4 亿之间,ViT 变种是 20 亿,GPT3 是惊人的1750 亿。
自动驾驶迟早也会达到这个规模。
模型平均每两年会增加 240 倍,内存带宽两年只会增加两倍。
SRAM 速度很高,高性能 AI 芯片需要尽量多的 SRAM。
SRAM 价格也高,差不多每 MB 价格是80-100 美元,通常 AI 训练用芯片需要 50MB 以上的 SRAM,也就意味着5000 美元的成本。
SRAM 需要6 个晶体管,并且晶体管之间的通道即有效宽度 Weff 在目前主流的 FinFET 工艺下,SRAM 的缩微很困难。
台积电 N3 即 3 纳米工艺,N3 具有 0.0199μm²的 SRAM 位单元大小,与 N5(5 纳米工艺)的 0.021μm² SRAM 位单元相比仅缩小了~5%。
改进后的 N3E(3 纳米扩展)变得更糟。
因为它配备了 0.021 μm² SRAM 位单元(大致转换为 31.8 Mib / mm²),这意味着与 N5 相比根本没有缩放,再延伸就是芯片的成本增加了,性能却没有。
目前 AI 模型尺寸越来越大,超过 20GB 已是常态。
使用 SRAM 来存储,芯片价格轻易突破100 万美元,即使是不太在乎价钱的服务器也承受不起。
因此,我们只能退而求其次——HBM,即 High Bandwidth Memory,每 GB 的 HBM 成本大约20 美元。
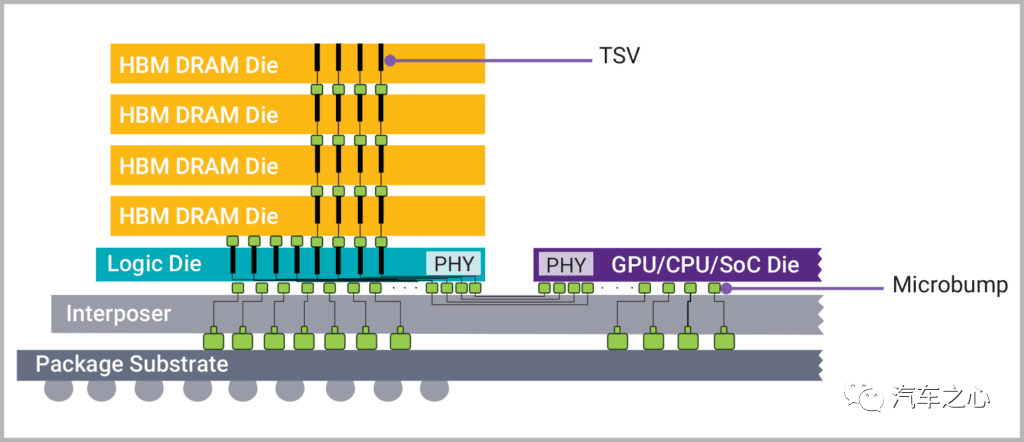
如上图,简单概括:
HBM 是将 SDRAM 用 TSV(硅通孔)工艺堆叠起来,如同盖楼,层和层之间会有金属层等间隔,同时通过 TSV 联通各个存储单元。
TSV 是内存能够堆叠的关键,它能够在各个存储层之间以及层内构建出硅通孔的通路,存储单元的访问就通过这些通孔完成。
在了解 HBM 之前,我们需要明白几个内存基本概念——密度、速度和带宽。
密度指的就是容量。
速度有两种描述,一是频率即MHz,另一种是MT/s,后一种方式越来越成为主流。
速度就好比高速公路的最高时速,带宽就好比高速公路的车道数。
HBM 是以牺牲速度来提高带宽的。
1MHz=1000KHz=1000000Hz 等于 1 秒内高低电平信号切换100 万次。
MT/s 全称 Million Transfers Per Second 意为每秒百万次传输。
1T/s 和 1Hz,这两个单位前者指的是每秒做了一次传输,后者指每秒 1 时钟周期。
因为 DDR 内存信号每个时钟信号可以传输 2 次,所以实际的传输速率为 1Hz 等于 2T/s,1MHz 等于2MT/s。
在 DDR5 发布后,内存性能规格的单位选择了 MT/s 为主,英特尔和金士顿、美光、威刚、芝奇等 PC 行业的领头企业也纷纷跟进这一策略,将内存性能的衡量单位改为MT/s。
对 CPU 来说,主要是串行数据流,速度就显得较为重要。
而 AI 和 GPU 是并行计算,带宽则比速度重要。
系统最大内存带宽= 内存标称频率*内存总线位数*通道数
实际内存带宽 = 内存标称频率*内存总线位数*实际使用的通道数
实际内存带宽=内存核心频率*内存总线位数*实际使用的通道数*倍增系数
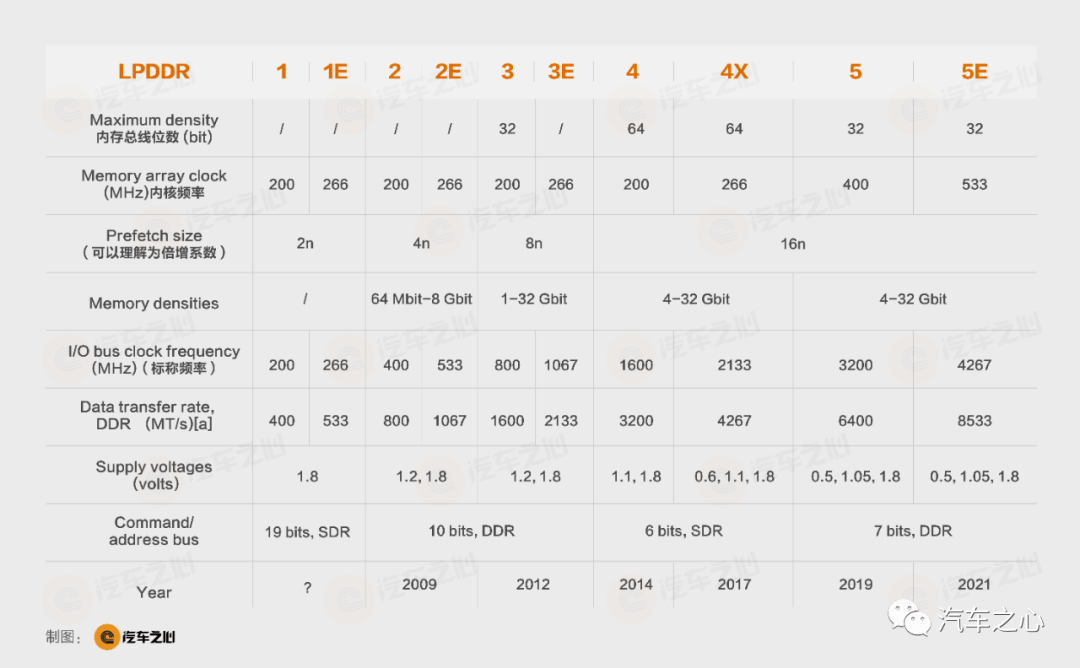
我们以车载领域的 LPDDR 为例来描述带宽:
历代 LPDDR 参数,注意位宽等同于 Maximum density,这是 CPU 一次能拿走的数据最大密度,用于 GPU 的最大密度就可以轻易达到 384bit。
特斯拉初代 FSD 使用的 LPDDR4,型号是 MT53D512M32D2DS-046 AAT,容量为 16Gb,总共 8 片,I/O 频率 2133MHz,单通道的话,其带宽为 2133*64*16,即 273GB/s。
HBM 采用物理堆叠,它的总线位宽可以是并联形式,每个 Die 有 2 个 128bit 位宽的通道,HBM1 只有 4 层堆叠叫做 4-Hi,带宽可以达到 4*2*128=1024bit,HBM2 的 I/O 频率是 1107MHz,倍频系数是 2。
以英伟达 V100S 加速器为例,用了 4 颗 HBM2,带宽是 1107*2*4*1028/8/1000,即 1134GB/s——比 LPDDR4 要高很多。
HBM3 频率提到 1600MHz,堆叠提高到 16 层,比 HBM1 高出 4 倍。
英伟达最新旗舰 H100 有多个版本,其中顶配使用 HBM3 内存 5 颗,每颗 16GB,带宽是 5*1600*2*16*1028,也就是3350GB/s。
HBM 通过基板的硅互联层与主处理器连接,物理距离远远小于 PCB 上内存与处理器之间的连接,几乎逼近 L3 缓存的连接距离,尽管其运行频率不高,但是这个速度是真实速度,没有任何水分。
另外需要指出的是,DDR 包括 LPDDR 和 HBM 这类存储,其真实的核心频率很低,在 133MHz 到 200MHz 之间。
不过为了数字漂亮,几乎没有厂家提到核心频率。
核心频率提高会导致功耗大增,这也是内存速度一直比较慢的真正原因。
来一张 H100 的高清大图:
H100 分两种,一种是SXM,另一种是PCIe。
H100 SXM5 的 INT8 算力峰值可达 4000TOPS,PCIe 是 3200TOPS。
注意 H100 主芯片旁边的 6 个紧贴着的芯片(有一个是空的,为了对称散热设计的,实际只有 5 个),那就是昂贵的 HBM3,由韩国 SK Hynix 提供。
目前全球只有 SK Hynix 能够量产 HBM3,也只有英伟达一个用户。
HBM 缺点一是贵,二是必须 3D 堆叠,三是散热不易。
因为它是堆叠的,考虑到成本比较高,只有服务器和 AI 训练领域才有人用 HBM,推理领域还未见到。
HBM 再退一步,就是今天的主角:GDDR。
02、为何特斯拉不惜血本用 GDDR6?
GDDR,可以说是廉价版 HBM。
GDDR 是 Graphics Double Data Rate 的缩写,是为 GPU 而生的内存。
GPU 和 AI 处理器,没有 L1/L2/L3 级缓存的概念,因为它的核心数量太多,不可能给每个核心配备缓存,那样做成本太高了。
GDDR 从第五代完全成熟,之前的四代都是基于传统 DDR,昙花一现生命周期很短,而 GDDR5 生命周期已经超过10 年。
GDDR5 最大提升是频率提高了 4 倍,采用了所谓 QDR 技术,DDR 是半双工,QDR 是全双工,它有两条数据总线,两条都可以同时读写。
比如 GDDR5 的 I/O 频率通常是 1750MHz,实际 I/O 频率是 1750*4=7000MHz。单颗 GDDR5 的带宽就是 32*7G/8=28GB/s。
GDDR6 再进一步,将预取 prefetch size 数据从 8n 增加到 16n,带宽再翻倍,单 bank 通常可达 56GB/s。
以特斯拉的 16 颗 GDDR6 为例,带宽是 56*16=896GB/s,是初代 LPDDR4 的 3 倍多,但跟 HBM3 差别还是很大。
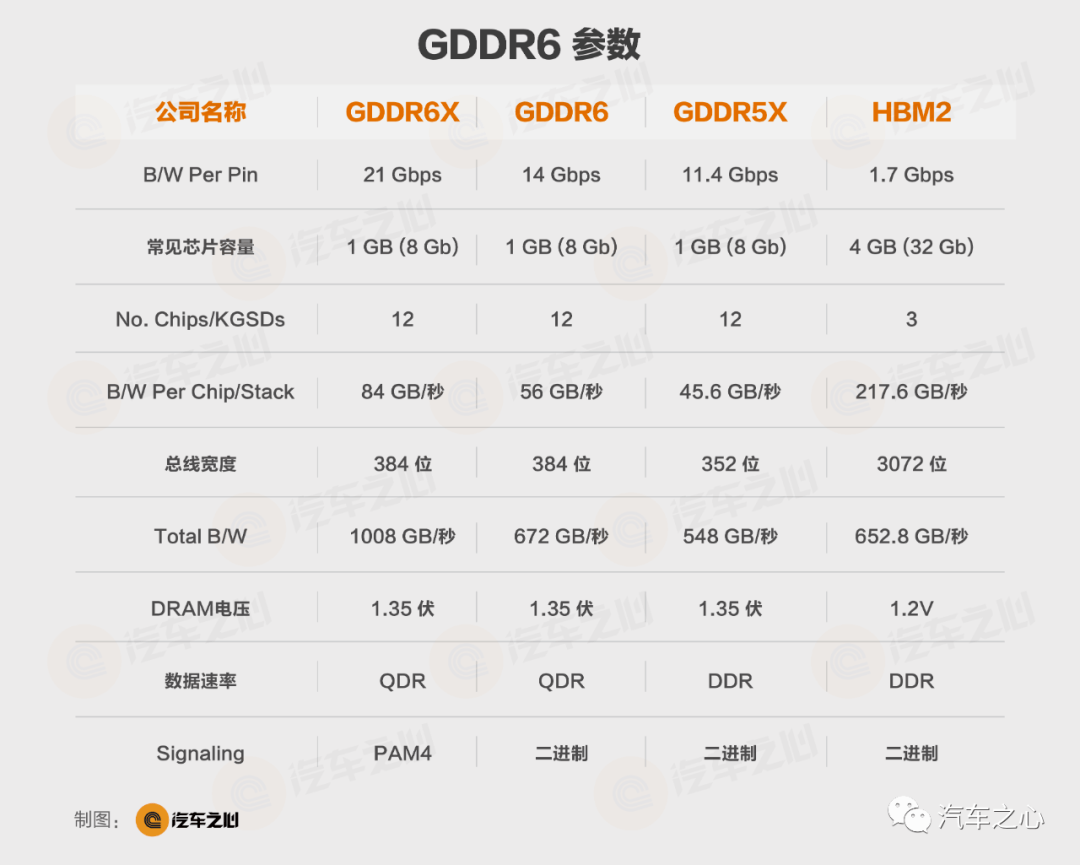
上图为各种 GDDR 参数对比:
GDDR5X 的总线是 352 位,就是最大支持 11 颗 32bit 的 GDDR 并联,合计总线宽度 352bit。
GDDR6 就是最大支持 12 颗 32bit 的 GDDR6 并联,合计总线宽度 384 位。
GPU 是并行计算,CPU 想做到这么高的位宽就比较困难。
2019 年开始出现 GDDR6X,也就是 GDDR7 的预演版,最大改变是引入 PAM4 编码,单颗达到 84GB/s,12 颗带宽超过1TB/s。
虽然理论上 GDDR6X 采用 PAM4 信号调制方式,配合 MTA 编码技术,GDDR6X 的能效提升很多。
同样是 8 颗显存,GDDR6X 能效比相比 GDDR6 的每比特能耗要低15%。
实际测试中,搭载 10GB GDDR6X 显存的 RTX3080 的显存功耗高达 70W,24GB GDDR6X 显存的 RTX3090 的显存功耗更是上到130W,是十足的耗电大户。
不过 GDDR 和 HBM 都是针对并行计算的,注重带宽,不注重速度。
GDDR6 的 CSA 延迟是 DDR4 的2 倍多,也就是说 GDDR 和 HBM 不适合用在 CPU 上。
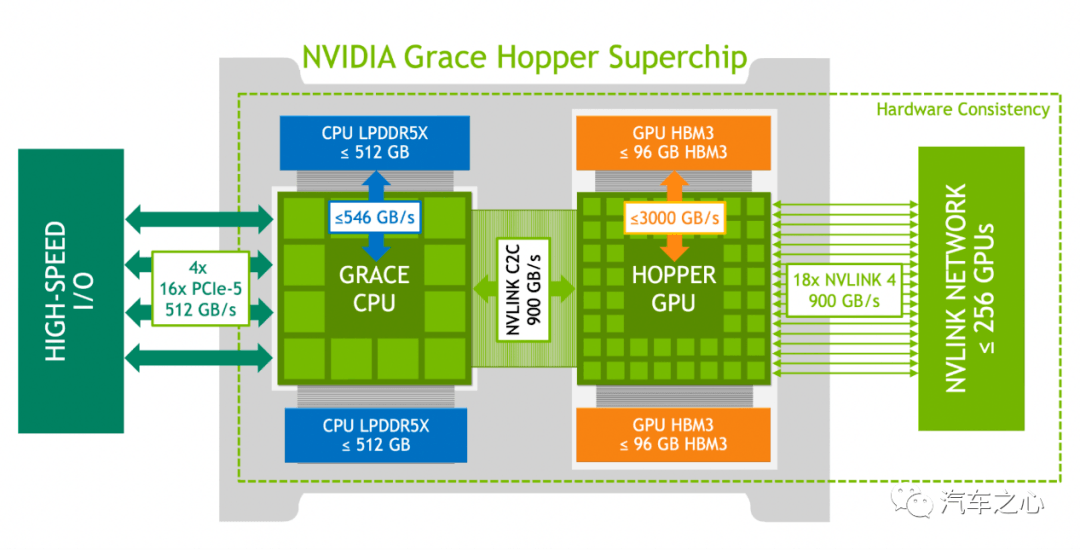
CPU 是有序列的串行运算为主,因此英伟达 Grace Hopper Superchip 的 CPU 部分还是使用了LPDDR5X。
而目前全球算力最高的设备,是大约 25 万美元的英伟达 DGX-H100,CPU 部分是英特尔的 Sapphire Rapids 即 Xeon W3XXX 系列(旗舰产品近 6000 美元一片)。
此前的 DGX-A100,CPU 是 AMD 的 EPYC Rome。
对应 CPU 的是 SK Hynix 的 DDR5,当然英特尔的 Xeon 做并行计算也可以,毕竟它是 56 核心。所以英特尔 Sapphire Rapids 也支持 HBM2E,但首选还是 DDR5。
特斯拉的二代 FSD 也有 CPU 部分,即 20 核心的 ARM Cortex-A72。
但特斯拉对 AI 算力更在意,或者说特斯拉有算力焦虑。
英伟达在算力方面太强大了,特斯拉宁肯弱化一点 CPU 也要上 GDDR6,并且是不惜成本。
特斯拉热衷于大模型,为了保证足够高的效率,我推测特斯拉三代 FSD 芯片估计要使用昂贵的 HBM3,至少要装下全部权重模型,估计容量不低于 50GB。
单这部分成本,就不低于 1000 美元,未来特斯拉三代 FSD 的成本最低也在 1500 美元以上。
同样,如果自动驾驶行业还热衷于人工智能,那么 5 年后的自动驾驶芯片成本最低也要2000 美元以上。
来源:第一电动网
作者:汽车之心
本文地址:https://www.d1ev.com/kol/197094
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!









 京公网安备
11010502033163号
京公网安备
11010502033163号