几个小时前,特斯拉正式举办了 2022 AI Day,一场全球汽车、人工智能、信息科技行业翘首以待足足 13 个月的发布会。

严格意义上 AI Day 不像是「发布会」,而是「交流会」——马斯克本人也在推特上说,「此活动旨在招聘 AI 和机器人工程师,因此技术含量很高」——换句话说,这是马斯克的高山流水,为特斯拉的锺子期而开。
不过这并不妨碍我们以比较轻松的视角,记录下这场科技狂欢。因为特斯拉团队几乎 100% 实现了去年的承诺,在本届 AI Day 上带来了以下技术成果:
不再需要群演的真·Tesla Bot 机器人原型机;
不再停留在 PPT 的 DOJO POD 人工智能超级计算机;
FSD 技术新进展,等等。
当然,即使我们会尽力写得简单点,今天的文章依然会相对硬核。趁着国庆假期,建议大家可以慢慢看,下面马上开始。
一、Tesla Bot 原型机
Optimus 它来了!

13 个月前还需要群演的 Tesla Bot,今天正式以原型机的形式出现——原型意思是它还没穿衣服(外壳)。

原型机的样子比 PPT 里面明显更粗放,线束、促动器等零件堆砌略显凌乱。但好消息是,Tesla Bot 原型机已经可以走路、打招呼,双手可以完整举过头顶。

在特斯拉的演示视频里,Optimus 已经可以做一些简单的工作,比如搬运箱子、浇花等等。



但更重要的可能是这个画面:Optimus 眼中的世界,通过纯视觉发现并分析周边的一切,然后识别出自己的任务对象。

事实上 Optimus 不是不能装上外壳,但出于工程原因,带外壳版本截止到发布会当天还不能自如地走路(原因后面再解释),只能简单挥舞一下手臂。

装上外壳之后我们发现,更接近量产版的 Optimus,变得更胖了——现在它重 73 公斤,比去年 PPT 版「增重」超过 20%,整个「人」圆了一大圈。
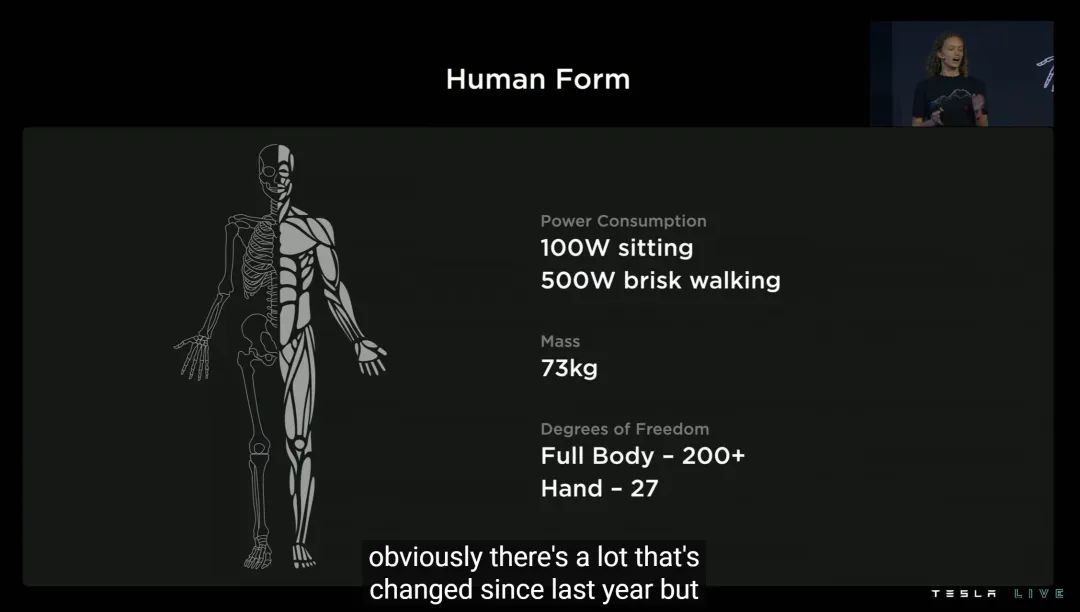
更接近量产,也意味着 Optimus 更高阶的参数也可以公布了:100W 静坐功耗、500W 快步走功耗、超过 200 档的关节自由度,光手部自由度就有 27 档。

另外,Optimus 的大脑由单块 FSD Chip 组成,意味着算力应该是 HW3.0 的一半(72TOPS);电池则是 52V 电压、2.3kWh 容量、内置电子电气元件的一体单元。
说完数字,是时候聊聊 Optimus 的研发逻辑了。
1. 汽车化
马斯克说过「当你能解决自动驾驶,你就能解决现实世界中的人工智能」。这句话点破了特斯拉研发 Optimus 的方法论:大量借鉴汽车研发经验。
比如借鉴汽车碰撞模拟软件,为 Optimus 编写「跌倒测试」软件。

再比如利用汽车大规模零件的生产经验,为 Optimus 挑选尽可能保证成本+效率的原材料。「我们不会用碳纤维、钛合金这样的原材料。因为它们虽然很优秀,但像肩膀这样的易损部位,制造和维修成本都太贵了」。

除此以外,制造 Optimus 的中心思想,也基本和智能汽车相当:减少线束长度、计算和电子控制单元中心化,等等。
2. 仿生学
既然是类人机器人 humanoid,设计自然要借鉴人类仿生学。
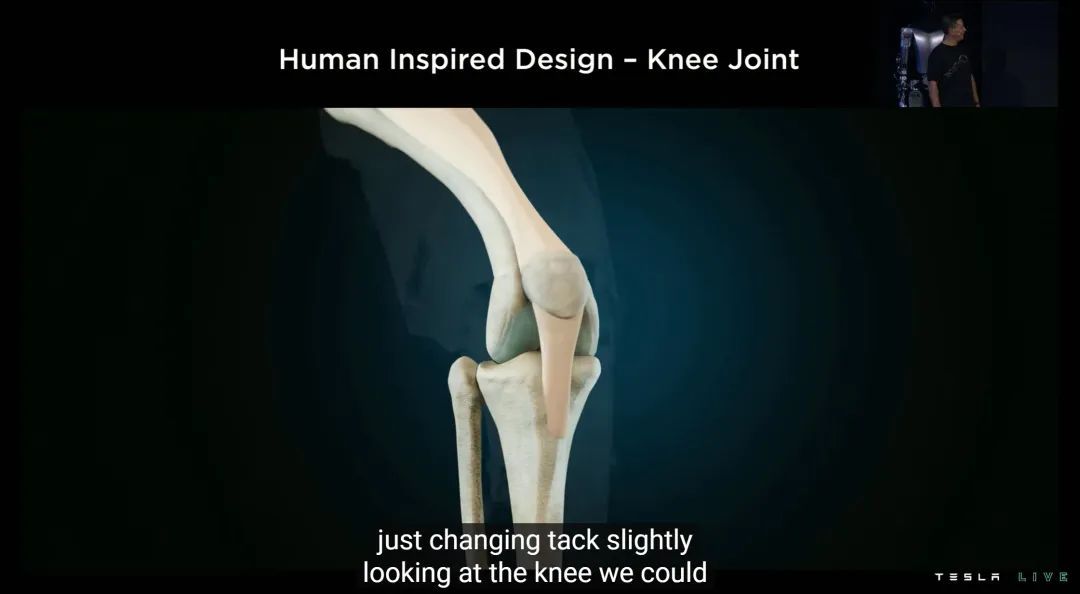
特斯拉用了几个例子解释 Optimus 的仿生学,首先是膝关节。特斯拉表示 Optimus 的关节希望尽量复刻生物学上的「非线性」逻辑,也就是贴合膝关节直立到完全弯曲时的受力曲线。

为此,Optimus 的膝关节使用了类似于平面四杆机构的设计,最终发力效果会更接近人类。

紧接着,我们创造人类文明的双手,才是 Optimus 类人之路更大的 boss。

Optimus 光手掌区域就用了 6 个促动器,具有 11 档的自由度。拥有自适应的抓握角度、20 磅(9 公斤)负荷、工具使用能力、小物件精准抓握能力等等。

此外,Optimus 的手掌用的是「non-backdrivable」无法反向驱动的指尖促动器。学术界的看法是,这样的促动器可以提升在「开放环境」下的性能。
最后是让 Optimus 学着像人类一样走路——这里用到的仿生学设计叫做「运动重心控制」。

为什么有外壳的 Optimus 还不会走?其中一个原因就是重量变了,运动重心控制算法需要重新调试。

事实上,Optimus 不仅要做到会走路,还要做到别摔倒。所以它不仅需要控制走路的重心,还要稳住受到外力(比如推搡)时的随机动态重心。

训练 FSD 用到的神经网络和在线仿真模拟,这次在 Optimus 身上大显身手。路径规划、视觉融合、视觉导航等等熟悉的名词都被「灌输」到 Optimus 脑子里。

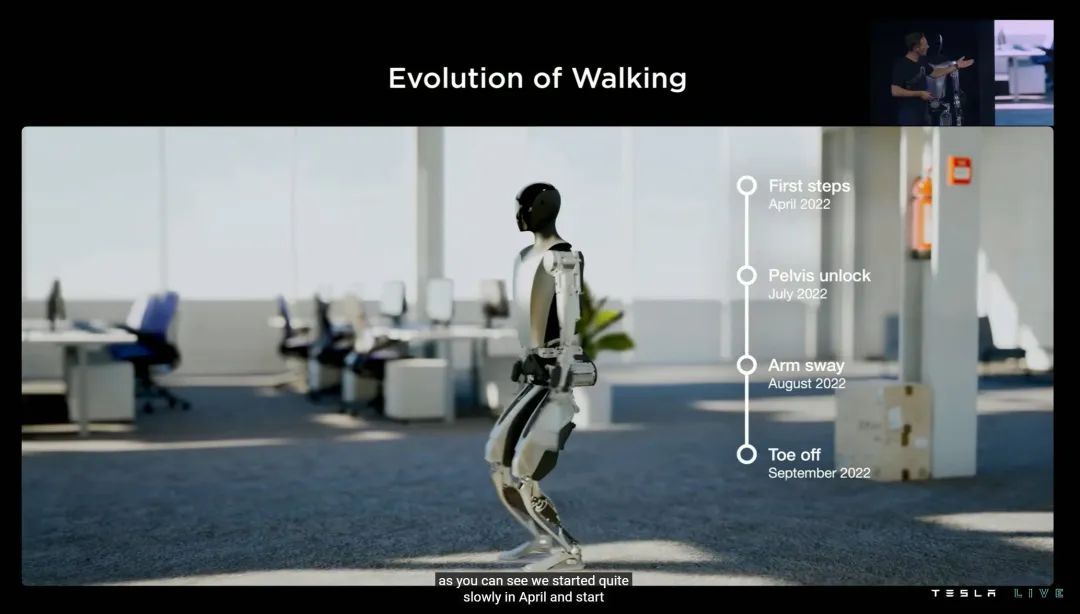
这样的努力下,Optimus 今年 4 月迈出了它的第一步;7 月份解锁了骨盆活动;8 月走路时可以摆手臂了——发布会前几周,实现了脚趾离地的类人行走动作。
3. 「肌肉」
我们通过结缔组织包裹着的肌肉完成运动,机器人的「肌肉」则叫做促动器 actuator。

如上图所示,橙色部分均为 Optimus 的促动器,这些促动器也都是特斯拉完全自研的。
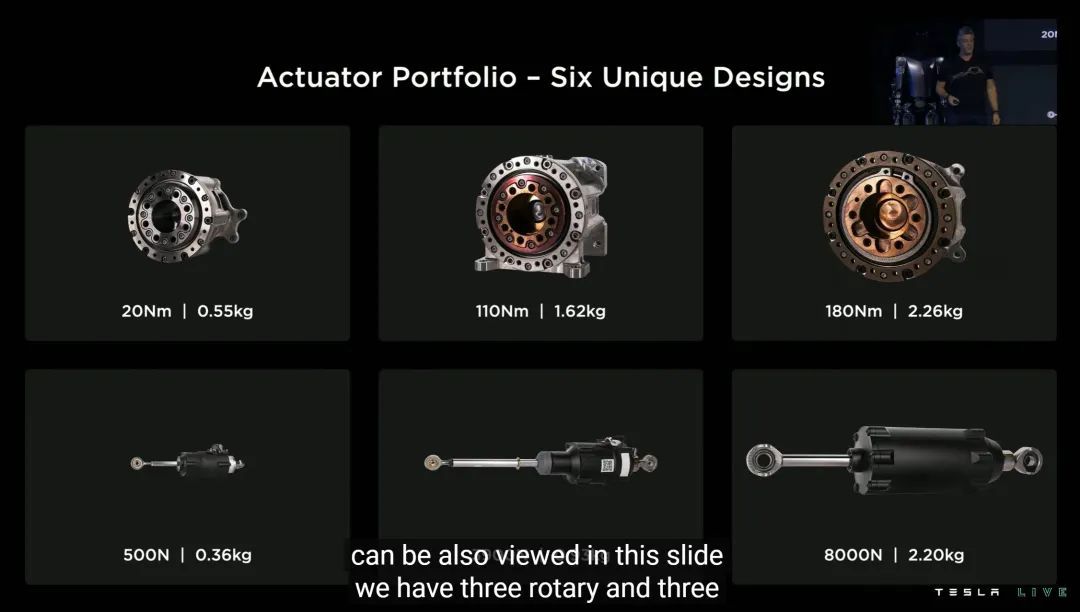
特斯拉为 Optimus 从力度大小的角度,设计了 6 种各自独特的促动器——这其实是很小的数字,业界平均是 20-30,甚至 50 种,目的是覆盖尽可能多的人类活动细节。
为什么特斯拉的促动器种类这么少?原因还是 FSD 体系。
特斯拉举了 28 种人类常见活动,比如抬举手臂、弯曲右膝等。通过分析这些活动反馈的云数据,找出各类运动的相对共同点,然后就可以尽量减少专门设计促动器的种类。
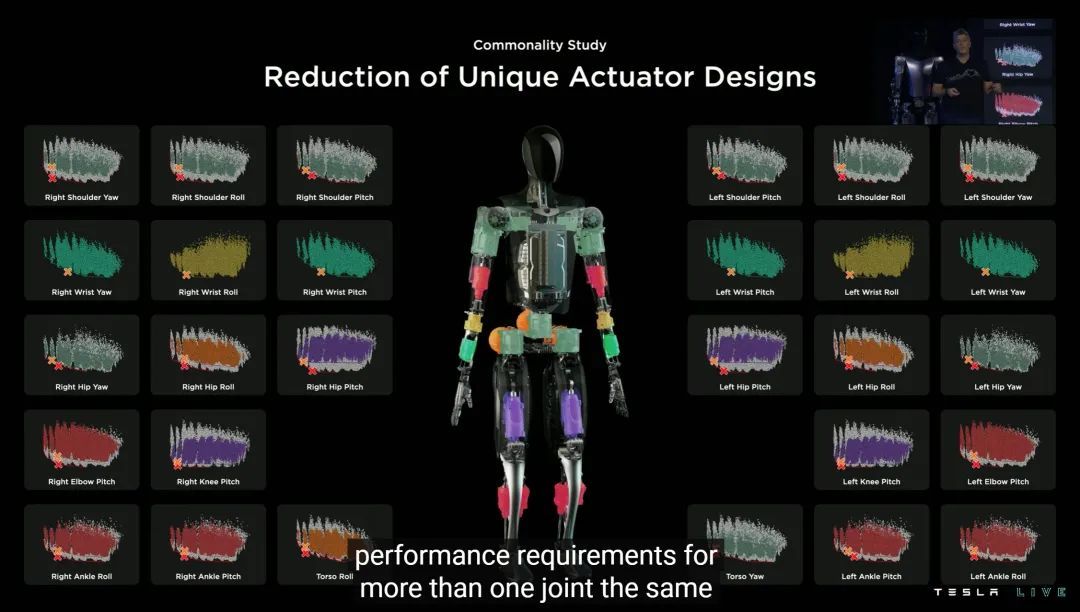
虽然只是轻描淡写的一张 PPT,但我认为促动器从 50 种减少到 6 种,意义实际上远大于借鉴特斯拉电机经验的促动器本体——因为它代表着数据为王的新工业时代。
不过促动器种类大幅度减少,也意味着 Optimus 前期的实际效果可能会没有那么「类人」,当然还是得等最终交付了。
最后来说一个数字:2 万美元(约 14 万元)。
这笔钱买不到半台 Model 3,但却是马斯克口中 Optimus 的目标售价。「它会彻底改变人类社会的效率,就像无人交通可以彻底改变运输效率」。
二、DOJO 的终极形态?
本来发布会的第二部分是 FSD,但那部分过于硬核,我决定先让大家看点激动人心的数字。
去年 DOJO 惊艳全世界,但遗憾的是有太多细节未公布。D1 芯片是怎么组成 EXA POD 超算系统的?理论性能爆炸,能代表实际应用吗?
这部分,特斯拉举了大量的数据,证明自己已经是计算领域的新巨头。

首先是散热。
先别发问号,超算平台的散热,一直是衡量超算制造者系统工程能力的重要维度。比如谷歌、华为、英伟达在公布自家方案的时候,都会花大篇幅讲散热。
DOJO POD 的散热可以用两个词概括:高集成度、高自研率。

特斯拉在 DOJO POD 上使用了全自研的 VRM(电压调节模组),单个 VRM 模组可以在不足 25 美分硬币面积的电路上,提供超过 1000A 的电流。
高集成度带来的问题,是热膨胀系数 CTE。DOJO 堪称极限的体积集成率和发热,意味着 CTE 稍微失控,都会对系统结构造成巨大破坏(也就是会撑爆)。
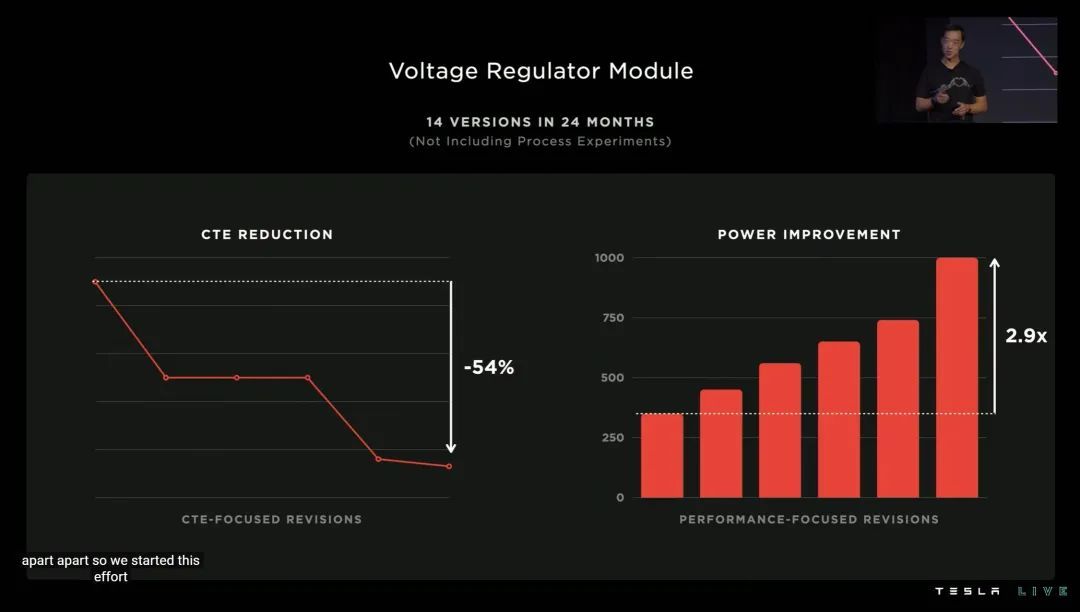
为此,这套自研 VRM 在过去两年内迭代了 14 个版本,最终才完全符合特斯拉对 CTE 指标的要求。
目前 DOJO POD 已经进入负载测试阶段——单机柜 2.2MW 的负载,相当于 6 台 Model Y 双电机全力输出。

解决了散热,才有资格说集成度。
一个 DOJO POD 机柜由两层计算托盘和存储系统组成。每一层托盘都有 6 个 D1 Tile 计算「瓦片」——两层 12 片 组成的一个机柜,就可以提供 108PFLOPS 算力的深度学习性能。

对了,DOJO POD 的供电模组也是 52V 电压的,Optimus 母亲实锤了。
每层托盘都连接着超高速存储系统:640GB 运行内存可以提供超过 18TB 每秒的运算带宽,另外还有超过 1TB 每秒的网络交换。

为了适配训练软件以及运营/维护,每个托盘还配备了专属的管理计算中心。

最终,可以提供1.1E 算力、13TB 运存、1.3TB 缓存的 EXA POD,将于 2023 年 Q1,正式量产——这也是今天发布会唯一一个有确定日期的特斯拉产品。

意大利炮有了,能不能轰下县城?
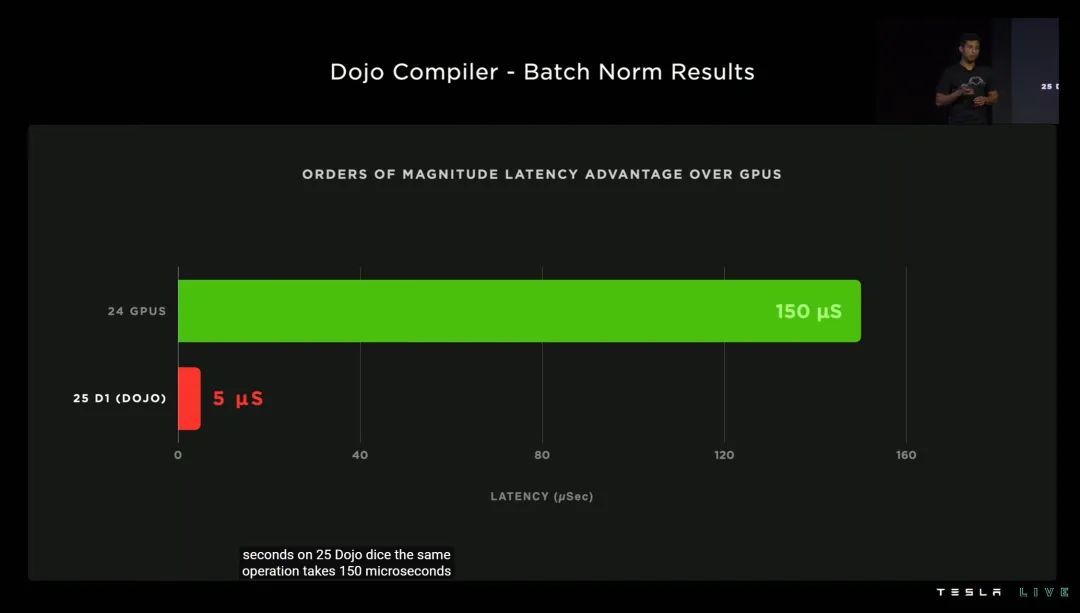
特斯拉表示,配合专属的编译器,DOJO 的训练延迟,最低可以做到同等规模 GPU 的1/50!
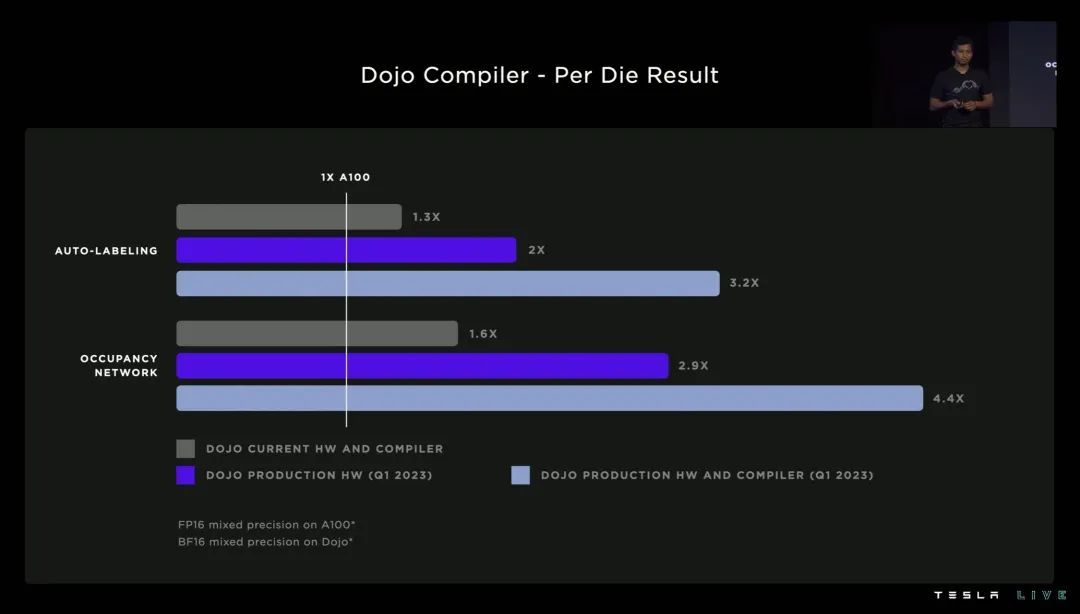
最终,特斯拉的目标是到 2023 年 Q1 量产时,DOJO 可以实现相比英伟达 A100,最高 4.4 倍的单芯片训练速度——甚至能耗和成本都更低。
三、FSD 的新进化
文章来到这里,大家的手指应该已经划了很多次屏幕。这也说明,看到这里依然兴致勃勃的你,一定是特斯拉老粉——那就聊点更「无聊」、更硬核的吧。

篇幅有限,本届 AI Day 关于 FSD 的进展,我们只聊三个点:Occupancy Network、Training Optimization、Lanes。
1. Occupancy Network
先聊一个概念:矢量图。做设计的朋友一定很熟悉,这是一种精度(分辨率)可以做到无限,但占用存储空间很小的数字绘图。
Occupancy Network,就是将 3D 向量数据绘制成矢量图的、 2019 年开始兴起的一种三维重建表达方法。
有意思的是,特斯拉用了最 Occupancy Network 的方式,表达他们对 Occupancy Network 的应用:网格(方块)化的 3D 模拟。
其实 FSD 眼中的世界并不是这样 Minecraft 化的,但 Occupancy Network 的本质特征,就是用「决策边界」描绘「物体边缘」。
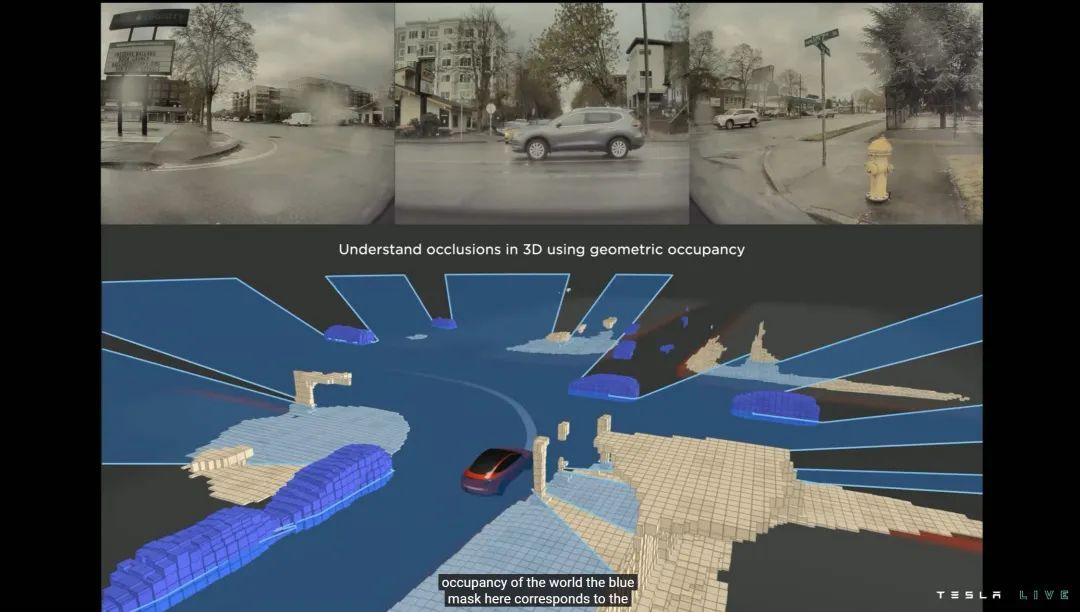
尽管 Occupancy Network 效率很高,但实际训练规模依然足够可观。目前特斯拉公布的数据是超过14.4 亿帧视频数据,需要超过 10 万个 GPU 训练小时,实际视频缓存超过30PB——而且全程 90℃ 满负载。

二、因此,Training Optimization 训练优化尤为重要。
去年 Andrej 公布了特斯拉的千人 in-house 标注团队,今年特斯拉的重点,则在于优化自动标注流程。
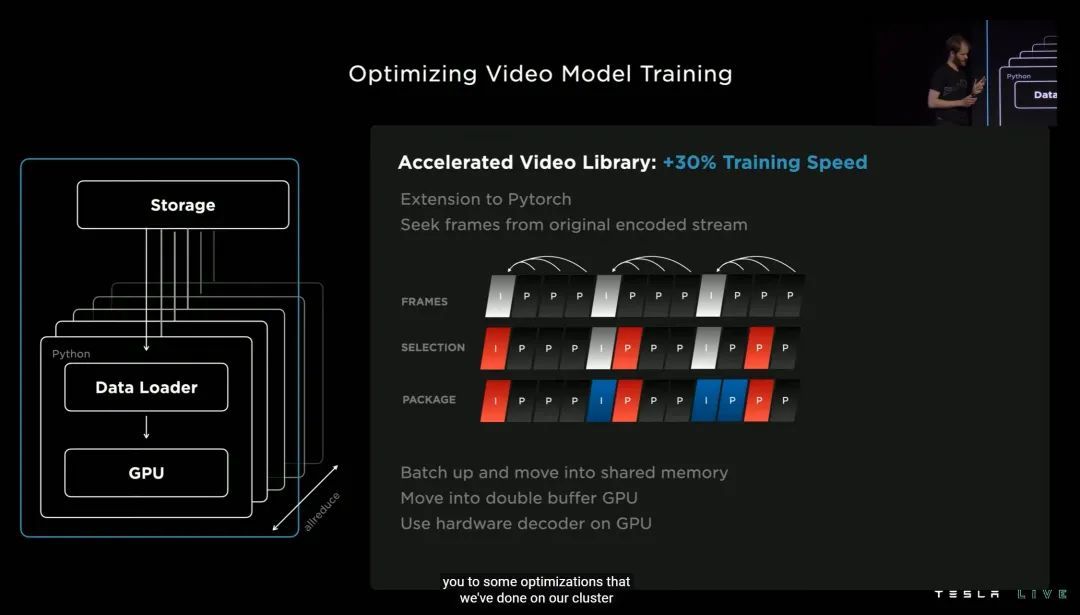
大概总结一下就是,优化过后,训练时视频帧选取会更智能,同时大幅度减少选取的视频帧数量——可以提高 30% 的训练速度。
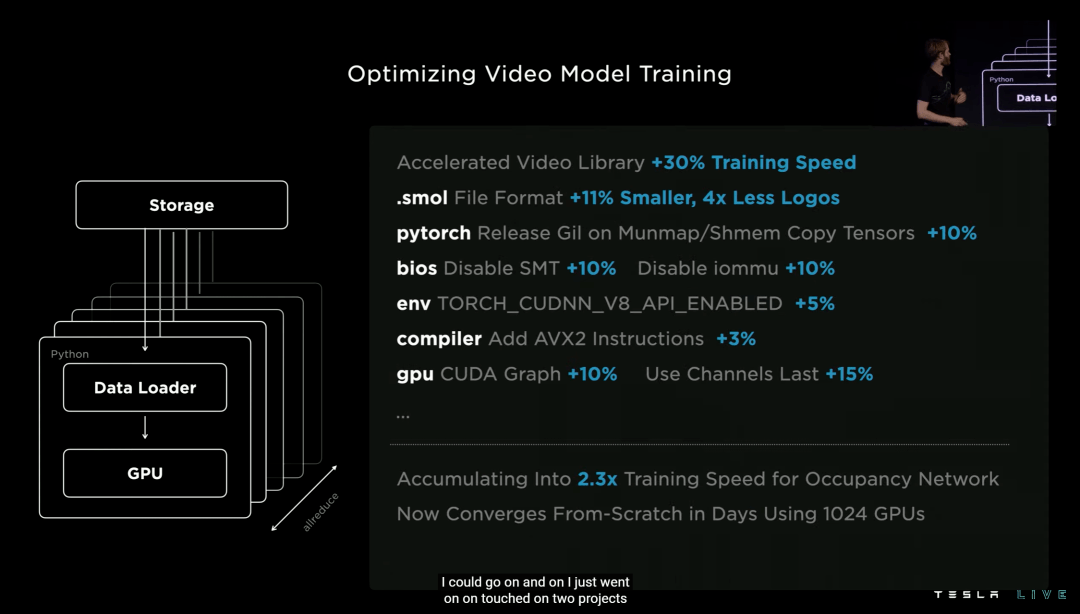
另外视频模型训练时 smol 异步库文件体积可以缩小 11%,所需的读取次数足足缩小到 1/4...最终这套优化流程让特斯拉的 Occupancy Network 训练效率提升了 2.3 倍。
3. 最后聊聊车道线 Lanes。
从 FSD Beta 10.12 开始,几乎每一版更新,车道线和无保护左转,都是更新日志的第一条。
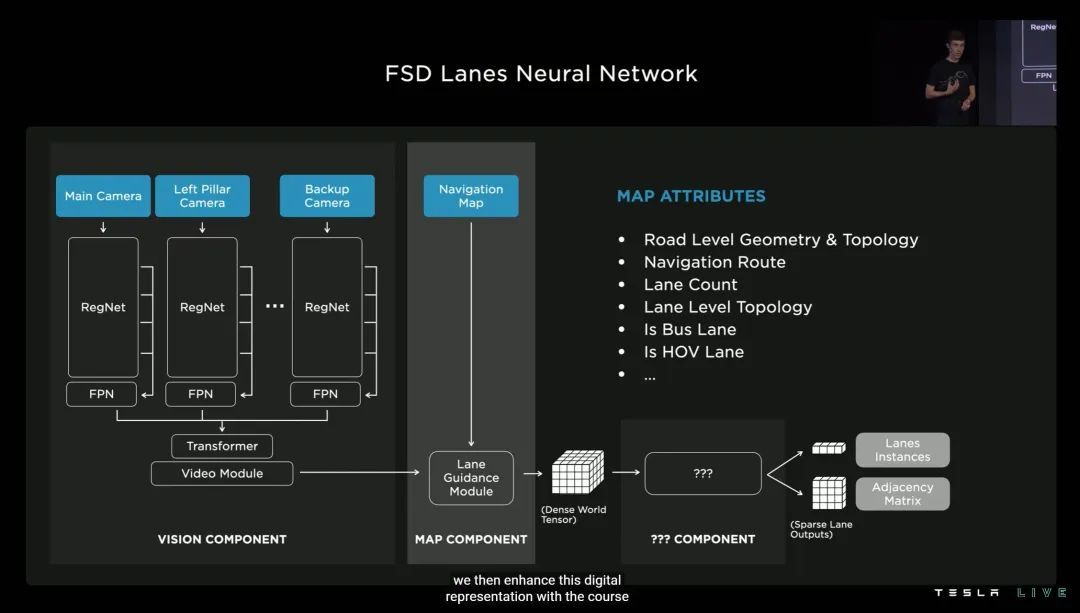
为了更准确高效应对车道线,特斯拉这次「编」了一套「属于车道的语言」。其中包括车道级别的地理几何学和拓扑几何学、车道导航、公交车道计算、多乘员车辆车道计算等等。
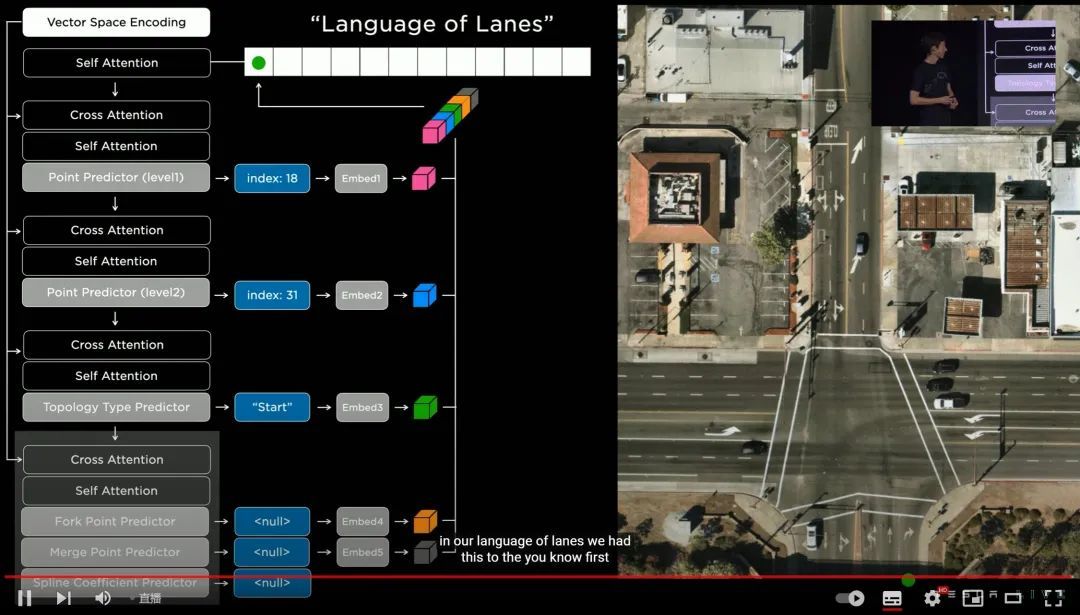
最终这套「车道的语言」,可以在小于 10 毫秒的延迟内,思考超过 7500 万个可能影响车辆决策的因素——而且 FSD 硬件「学会」这套语言的代价(功耗),还不足 8W。

四、四十年后,开始圆梦?
写到这里,我真的很头疼。
一方面是我们大部分人,都不是这届 AI Day 的对象——马斯克眼里只有招聘。另一方面,是现在一家汽车公司的发布会,对知识面要求实在太高了。

还是说回马斯克吧,40 年前的他,还是个每天会看 10 个小时科幻小说的小孩子,沉醉于《银河系漫游指南》、《基地》、《严厉的月亮》等等。
但正是这些科幻小说,培养了马斯克冰冷却又宏大的事业观。他会跟你说人类社会生产力的效率可以扩大到无限,他会跟你说人口是维系文明的最重要因素。
所以,当我们把 52 岁的马斯克和 12 岁的马斯克放在一起,你会发现他俩依然在本质上是同一个人。
也正因如此,你看到他如今几乎涉猎了科幻小说所有最热门题材的商业帝国,才会觉得「哦,那很正常」。
希望明年我们能看到更接近现实的马斯克童梦吧。
(完)
来源:第一电动网
作者:电动星球News蟹老板
本文地址:https://www.d1ev.com/kol/186317
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。


相关话题
相关圈子


先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!











 京公网安备
11010502033163号
京公网安备
11010502033163号