汽车产业已经“死气沉沉”好久了,与“一年一小变,三年一大变”的互联网产业相比,过去的几十年来,它都没有发生多少颠覆性的变化。然而,三十年河东,三十年河西,在即将到来的自动驾驶时代,汽车产业或将成为互联网产业“羡慕嫉妒恨”的对象。
我们如此看好汽车产业在自动驾驶时代的前进速度,并不是因为汽车制造商掌握了什么绝技,而是自动驾驶系统所使用的核心芯片,正在以远超”摩尔定律“的速度孜孜不倦地自我迭代着。

促使我们注意到自动驾驶芯片这种“进取心”的,是英伟达于10月11日发布的L5级无人驾驶计算平台Drive PX Pegasus。对这款Drive PX Pegasus,如果用两个字评价,那就是“牛逼”;用四个字评价,就是“相当牛逼”。要想知道它究竟有多牛逼,还得先跟英伟达的现有产品做个比较——目前,特斯拉的Autopilot 2.0上使用的Drive PX 2每秒钟可完成24万亿次深度学习计算操作,而Drive PX Pegasus每秒钟可完成的深度计算操作是320万亿次!也就是说,在深度学习计算这个最重要的能力上,Drive PX Pegasus比Drive PX 2强出12倍还多!
从发布时间上看,Drive PX Pegasus比在2016年1月份的CES展上亮相的Drive PX 2晚了21个月。21个月计算能力增强12倍,这算是彻底震撼了“摩尔定律”——根据摩尔定律,21个月以内计算性能翻一倍才是“正常”的。
再回过头去看从Drive PX 到Drive PX 2的进步,时间跨度是从2015年1月份到2016年1月份,刚刚12个月;而在这12个月里,英伟达无人驾驶计算平台的计算能力也是进步了10倍(深度学习计算性能从2.3万亿次/秒增长到24万亿次/秒)! 这个进步速度,仍然是超出了摩尔定律的“解释能力”。
也难怪,英伟达创始人黄仁勋曾多次在公开场合说“摩尔定律已死”。不过,与此前很多IT界人士质疑“摩尔定律是否已经过时”是暗指芯片性能的进步速度正在放缓不同的是,黄仁勋所说的”摩尔定律已死“,意思是,在AI时代,GPU的进步速度要超过在摩尔定律下CPU的进步速度。
GPU换代周期缩短,增长倍率变大
从24万亿次/秒到320万亿次/秒,Drive PX Pegasus的深度学习能力已经是诞生于21个月之前的“上一代”的13.3倍;与更早的Drive PX的相比,在不到3年的时间里,它的性能已经增长了将近140倍!
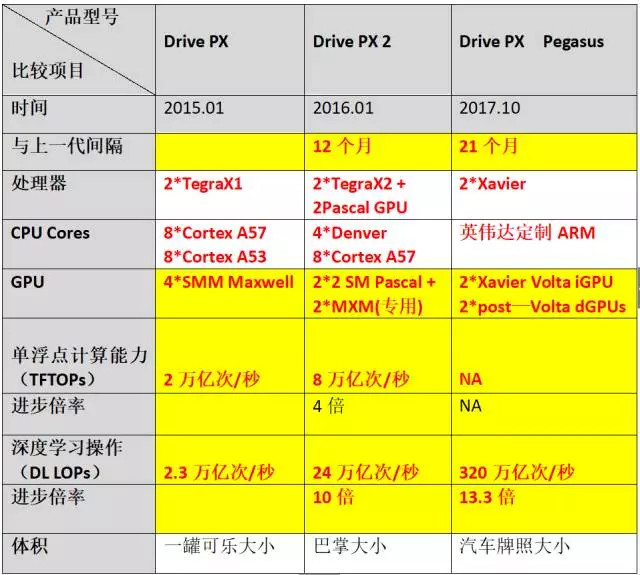
或许,有细心的人要质疑了:摩尔定律说的是芯片的计算能力,可你这里提到的Drive PX系列无人驾驶计算平台,都是集成产品,而非“原始芯片”,因此不能拿它的“进步曲线”来跟摩尔定律做比较。 这个质疑是有道理的,不过,我正想补充的是,Drive PX系列的计算性能“每一代比上一代进步10倍”,除去CPU的配置显著提升外,更关键的原因正是它们所用的GPU的性能也提升了大约10倍!
GPU的计算性能与其在设计时采用的架构模式高度相关。Drive PX采用的GPU是基于Maxwell的TeslaM40;Drive PX 2采用的GPU是基于Pascal的TeslaP100;Drive PX Pegasus采用的GPU有两颗是基于Volta的TeslaV100(上表中提到的Xavier,是在TeslaV100的基础上集成而来的Soc),还有两颗是尚未发布的继Volta之后的“下一代”。
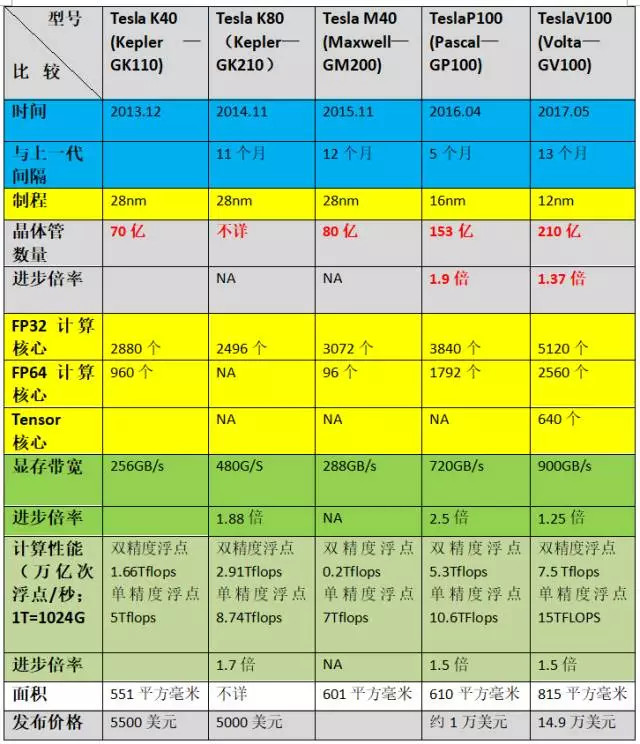
从上表可见,从2013年12月至2015年12月这两年,GPU的提升速度很慢,甚至,与前代相比,TeslaM40在某些单项指标上还出现了严重倒退。但在TeslaM40之后,GPU的更新明显加快——代际更新周期通常为6-12个月,计算性能的进步倍率通常在1.5倍左右。如果把周期延长到18个月,TeslaV100相比于TeslaM40,晶体管数增长至后者的2.6倍,显存带宽增长至后者的3.1倍,单精度浮点计算性能超过后者的2倍。
各单项指标的进步组合在一起后,在“乘数效应”的作用下,据英伟达方面曾在2016年的发布会上宣称,从TeslaM40到TeslaP100,GPU的整体性能提升了大约10倍;此外,据专注于人工智能的科技媒体雷锋网早先的报道,相比于基于Pascal架构的TelsaP100,基于Volta的TelsaV100将深度学习训练速度提升了12倍、深度学习推理速度也提升了6倍,综合性能提升也在10倍以上。
6-12个月,芯片(GPU)的新能就曾提升10倍,实在可怕!由于GPU基本上是英伟达的天下,在这里,恐怕已经有一个“黄仁勋定律”了吧?IT界的其他人困惑“如果摩尔定律消失,我们该何去何从”的时候,大多充满了忧虑,而黄仁勋在说“摩尔定律太老了,太慢了,GPU才是全新的‘超级摩尔定律’”的时候,应该是志得意满的吧?——言外之意是,属于英特尔的时代已成为过去,属于我黄仁勋的时代正在到来。
作为佐证的是,9月27日上午,在NVIDIA全球GTC北京站上,黄仁宇特别强调:“我们不会做那些每一次好一点点的通用性的处理器(CPU),而是要做在一些专门的领域,性能极好的处理器(GPU)。” 在黄仁勋眼里,摩尔定律下CPU性能的“每18-24个月翻倍”居然只是“每次只好一点点”,这是在公然羞辱英特尔吗?
宿敌的芯片也遵循“黄仁勋定律”
对黄仁勋反复“鄙视”摩尔定律并“诅咒”它“已死”,作为摩尔定律的“既得利益者”的英特尔,肯定会回复一个大大的“不服”,然后,再连加三个“感叹号”。
9月19日,在北京举行的“英特尔精尖制造日“活动上,英特尔向公众展示了10nm晶圆,并透露他们已经前瞻到了5nm制程。通过展示这些看家本领,英特尔旨在强调“摩尔定律不仅没有过时,而是一直在向前发展’。
不过,嘴硬归嘴硬,眼睁睁地看着昔日的“小屁孩”英伟达的股票一年涨了2倍、两年涨了8倍,曾经“一统江湖”的英特尔一定是很焦虑的。它已经错过了移动互联网时代,不能再错过AI时代了。英特尔在2016年以167亿美元收购世界第二大FPGA公司Altera、在2017年以153亿美元收购全球第一大ADAS供应商Mobileye,正是为了应对这种焦虑。
在AI领域,FPGA因具有“可编程”、灵活性强及功耗低的特性,在某些方面具备跟GPU一争高下的能力。然而,从“代际更新“的角度看,FPGA仍然跳不出摩尔定律的”局限性“。
下图为英特尔旗下Soc FPGA产品的Arria 系列
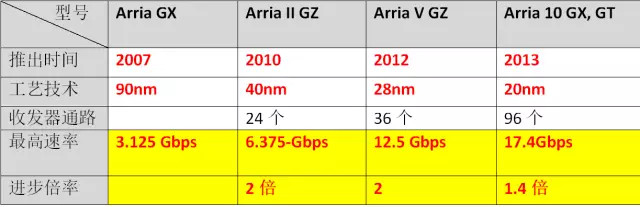
Arria 系列Soc FPGA芯片在更新换代时,仍然遵循了“每18-24个月计算性能翻一倍”的老规律。
不过,英特尔的另一个孩子Mobileye所造的芯片,在进步速度上却“很争气”。
Mobileye生产的EyeQ系列芯片,是为自动驾驶汽车的ADAS系统专用的,其中,EyeQ3曾经用在特斯拉的Autopilot 1.0上。Mobileye很能沉得住气,在这个热钱与泡沫齐飞的浮躁年代里,它却坚持“八年磨一剑”,自1999年成立后就一直踏踏实实做研究,直到2007年才发布了第一款拥有ADAS的芯片EyeQ1。但他的芯片一经发布,就开始了“指数级成长”。
下图为Mobileye EyeQ系列芯片的“迭代”路径:
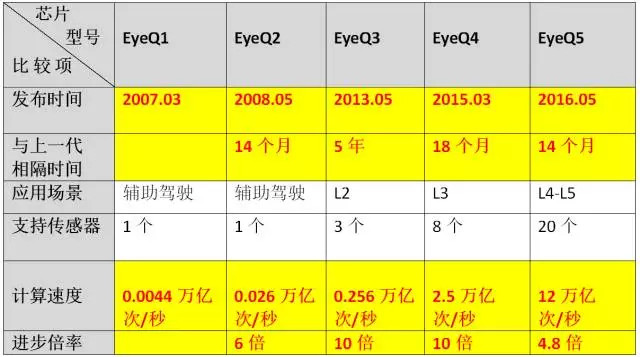
从EyeQ1到EyeQ2,芯片的计算新能在14个月内增长至原先的6倍,远远超出摩尔定律;
从EyeQ2到EyeQ3,计算能力在5年里增长至原先的10倍,虽然速度变慢,但跟摩尔定律相比并不算太逊色(按摩尔定律,24个月翻一倍的话,应该是48个月翻两番,计算能力增长至原来的4倍,或者,18个月翻一番,应该是54个月翻三番,增长至原来的8倍);
从EyeQ3到EyeQ4,计算能力在两年内增长至原先的10倍;
从EyeQ4到EyeQ5,计算能力再在1年内增长至原先的将近5倍......
这些都说明,虽然英特尔和Mobileye长期以来都视英伟达为劲敌,但它自家产品的进化,却依然得遵守了“黄仁勋定律”。
在收购Mobileye之前(2016年8月),英特尔曾以4.08亿美元收购了AI芯片创业公司Nervana Systems,并声称将在2020年之前将深度学习训练速度提升100倍。在摩尔定律主宰的“旧时代”里待久了的人,可能会觉得“提升100倍”是吹牛逼,但在AI时代的“黄仁勋定律”下,三年提升100倍,其实不是多困难的事情——
因为,6*6*6=216,再不济,也可以通过5*5*5=125来提前实现目标。
TPU:速度已经很牛逼,但加速度还需努力
很早之前,谷歌就意识到GPU更适合训练,却不善于做训练后的分析决策,因此,它得自己开发一款专门用于做分析决策的AI芯片。在低调使用了一两年后,在2016年5月份召开的Google I/O大会上,这款专用芯片TUP终于闪亮登场了。
谷歌声称TPU(以下简称TPU 1)的运算速度“比当前CPU和GPU快15-30倍”,但很快遭到黄仁勋及其拥护者的“打脸”,他们纷纷表示,谷歌是拿自己新出的产品跟英伟达两年前的旧产品TeslaK80做比较,不太厚道。甚至,直到谷歌在2017年推出新一代TPU即TPU2时,英伟达方面也称,他家的最新款GPU Tesla2V100在计算性能可以秒杀TPU2。
尺有所长,寸有所短,TPU是满足特殊功能的专用芯片,那它去跟GPU做PK,似乎也不太妥当。现在,我们放下这种不同产品之间的横向比较,只在同种产品的代际间做纵向比较。
别的不说,就看最重要的计算能力:TPU 1每秒可提做23万亿次16位整数的运算提,TPU 2可以达到每秒45万亿次的浮点运算。计算能力只增长了一倍。
TPU 1的开发时间为2013年前后,TUP 2的开发时间暂无可查询。如果TPU 2的开发时间在2015年之前,TPU 1到 TPU 2,芯片计算能力的提升幅度,刚好在摩尔定律的范围内,或者,比摩尔定律稍微快一点,但也没有明显优势;但如果TPU 2的开发时间在2015年之后,那么,从TPU 1到 TPU 2,芯片计算能力的进步速度是落后于摩尔定律中的速度的。
尽管谷歌口口声声称自己的TPU比GPU“快得多”,但在加速度方面,它充其量只能跟摩尔定律下的CUP相比,跟GPU和EyeQ的计算能力“每12-24个月翻10倍”的加速度相比,它还是慢了很多。
在“黄仁勋定律“下,芯片的架构研究很重要
最近,无人驾驶初创公司地平线创始人余凯在新智元举办的一次论坛演讲中谈到“新摩尔定律”。“最近大家也发现在物理上面,可能摩尔定律已经在逼近它的物理极限,英特尔本身自己也在减少自己往前递进的速度。这里打一个问号,我们怎么样保持摩尔定律?”
余凯自己给出的答案是:实际上还是可以做到的,手段不是通过物理上的工艺提升,而是通过软件算法的变革带来研发一些新的架构。随着摩尔定律越来越接近工艺极限,芯片的架构设计变得越来越重要。
“如果能研发出新的架构,在特定的目标应用场景上面,我们还能不断地往前发展。打个比方,我们人类的大脑实际上是有通用处理器的部分。有很多专用的硬件,比如听觉的、视觉的神经网络结构,包括有研究在三年前发现了在人脑里面有一个地方是专门用来做定位的。就是说,因为特殊目的去定义的这个硬件,使得你对特定的问题效率可以更高,新的摩尔定律可以继续往前奔跑,这个是新的摩尔定律。”
余凯这里所说的”新摩尔定律“,实际上就是本文在前面提到的”黄仁勋定律“。而他所说的通过”研发新架构“来改变进步速度,恰恰可以从英伟达的GPU随着架构从Kepler—Maxwell—Pascal—Volta改变,GPU的整体性能也飞速进步中得到印证。
一点疑问
前文讨论“摩尔定律”和“黄仁勋定律”,都是单从产品性能、技术进步的角度谈,却回避了价格的问题。摩尔定律的一个前提是“价格不变”,但AI芯片在更新换代时,价格往往会有很大的提升,比如,GUP TeslaP100发布时的价格是1万美元,而 TeslaV100的价格则是14.9万美元,完全不在一个量级。
从以往的规律看,新开发芯片的可以通过出货量的增长降下了,只是,不太确定,TeslaV100从天价降到“平民价”,需要达到怎样的出货规模才可以实现?需要等待的周期是多长?
来源:第一电动网
作者:建约车评
本文地址:https://www.d1ev.com/kol/57709
本文由第一电动网大牛说作者撰写,他们为本文的真实性和中立性负责,观点仅代表个人,不代表第一电动网。本文版权归原创作者和第一电动网(www.d1ev.com)所有,如需转载需得到双方授权,同时务必注明来源和作者。
欢迎加入第一电动网大牛说作者,注册会员登录后即可在线投稿,请在会员资料留下QQ、手机、邮箱等联系方式,便于我们在第一时间与您沟通稿件,如有问题请发送邮件至 content@d1ev.com。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号